





With over a decade of interdisciplinary experience, I have thrived in roles as an educator, researcher, and data analyst. My teaching portfolio covers a range of subjects, including Information Behavior, Finance, Tax Accounting, and Application of Computer in Accounting. As a researcher, I have contributed to projects like the Mobile Futures initiative, focusing on trust and values in European labor markets. My expertise in data analytics, particularly with Python, has enabled me to generate impactful insights into societal challenges and deliver actionable outcomes.
I thrive on autonomy in both academic and professional settings. Whether independently delivering courses or conducting complex research, I take initiative to ensure high-quality outcomes. My ability to manage diverse tasks—from teaching advanced concepts to performing data-driven investigations—demonstrates my self-reliant approach to problem-solving and innovation.
Collaboration and active engagement are at the core of my work. As a dedicated educator, I involve students through interactive learning and group assignments. In research, I engage with interdisciplinary teams to explore critical topics like cross-cultural behavior and immigration attitudes. My commitment to teamwork ensures that my contributions consistently enhance project outcomes and learning environments.
 I engage in interdisciplinary research on scientific misinformation, examining how media misrepresentation and retracted articles shape public perceptions and decision-making. My role involves:
I engage in interdisciplinary research on scientific misinformation, examining how media misrepresentation and retracted articles shape public perceptions and decision-making. My role involves:
✔ Conducting survey-based and media content analysis on science communication and public trust.
✔ Applying NLP, Python (pandas, NumPy, scikit-learn), and SEM to detect patterns in large-scale datasets.
✔ Designing and analyzing public opinion surveys related to trust in scientific information.
✔ Collaborating with researchers across disciplines to produce peer-reviewed articles and public outreach materials.
 I immersed myself in data-driven migration research, analyzing European Social Survey data to understand how trust and information exposure influence European managers’ attitudes toward immigrants. My role involved:
I immersed myself in data-driven migration research, analyzing European Social Survey data to understand how trust and information exposure influence European managers’ attitudes toward immigrants. My role involved:
✔ Data processing, cleaning, and visualization using Python, pandas, NumPy, and Matplotlib.
✔ Developing statistical models such as regression analysis and Structural Equation Modelling (SEM) to uncover hidden insights.
✔ Applying machine learning techniques to detect trends in large-scale migration data.
✔ Collaborating with interdisciplinary researchers to translate data insights into impactful policy recommendations.
 During my doctoral research, I delved into the intersection of information science, health behavior, and digital ecosystems. My work focused on understanding how immigrants navigate digital health information landscapes in Nordic countries. Key contributions:
During my doctoral research, I delved into the intersection of information science, health behavior, and digital ecosystems. My work focused on understanding how immigrants navigate digital health information landscapes in Nordic countries. Key contributions:
✔ Conducted both qualitative and quantitative research, utilizing NVivo for thematic analysis, SmartPLS for structural equation modeling, and SPSS for statistical testing.
✔ Designed and analyzed large-scale surveys, exploring immigrant health information-seeking behavior.
✔ Lectured in Information Behaviour 1 & 2, mentoring students on digital literacy, data analytics, and health information systems.
![]() I engaged in humanitarian fundraising efforts, ensuring sustainable financial support for crisis response initiatives. My contributions included:
I engaged in humanitarian fundraising efforts, ensuring sustainable financial support for crisis response initiatives. My contributions included:
✔ Securing donor commitments through impactful face-to-face interactions.
✔ Ensuring compliance with data privacy regulations while handling donor information.
 I navigated the intricate world of financial compliance, auditing, and risk assessment, delivering precise financial evaluations. My key responsibilities:
I navigated the intricate world of financial compliance, auditing, and risk assessment, delivering precise financial evaluations. My key responsibilities:
✔ Conducted financial audits and compliance checks across various industries.
✔ Designed custom financial reporting spreadsheets in Microsoft Excel, improving efficiency and accuracy.
 In this leadership role, I spearheaded the transformation of financial operations by integrating enterprise financial management software. Key achievements:
In this leadership role, I spearheaded the transformation of financial operations by integrating enterprise financial management software. Key achievements:
✔ Managed financial reporting, budgeting, and taxation, ensuring seamless financial operations.
✔ Led a digital transformation project, transitioning operations to Hamkaran System’s enterprise software.
✔ Developed SQL-based custom reports, optimizing data analysis for strategic decision-making.
My early career in accounting honed my skills in financial operations, bookkeeping, and data analytics. Key responsibilities:
✔ Managed daily financial transactions, ensuring accuracy in financial reporting.
✔ Designed Excel-based financial tracking tools, improving data-driven decision-making.

I’ve built a strong foundation in data-driven decision-making by working with analytics, machine learning, and data engineering across several courses. Through this specialisation, I developed the ability to turn complex data into meaningful insights and practical solutions.
Along the way, I gained experience in:
✔ Introduction to Analytics (5 ECTS) – Learning the fundamentals of data processing, statistical analysis, and how to use data to support decision-making.
✔ Machine Learning for Predictive Problems (5 ECTS) – Building models to forecast trends and make informed predictions based on data.
✔ Visual Analytics (5 ECTS) – Communicating insights clearly through data visualization and interactive dashboards.
✔ Machine Learning for Descriptive Problems (5 ECTS) – Exploring data with unsupervised learning techniques to uncover patterns and relationships.
✔ Cloud Computing and Data Engineering (5 ECTS) – Working with modern data infrastructure and tools to manage, process, and scale data solutions.
✔ Service Design (5 ECTS) – Understanding how to design user-centred services and connect data insights with real-world business needs.
 I embarked on an enriching journey into pedagogical sciences, blending theory with practice to master the art of teaching, guidance, and competency-based learning. This internationally recognized qualification equips me with the skills to teach in vocational institutions and universities of applied sciences, as well as to develop staff training programs in corporate and professional settings.
I embarked on an enriching journey into pedagogical sciences, blending theory with practice to master the art of teaching, guidance, and competency-based learning. This internationally recognized qualification equips me with the skills to teach in vocational institutions and universities of applied sciences, as well as to develop staff training programs in corporate and professional settings.
Through collaborative and diverse learning environments, I am gaining expertise in:
✔ Curriculum planning & educational theory
✔ Teaching in multicultural & digital classrooms
✔ Guidance methods and competency-based assessment
✔ Networking & fostering well-being in educational settings
This program strengthens my ability to develop learning environments that adapt to evolving professional landscapes, ensuring that education remains dynamic and inclusive.
 I immersed myself in the field of Information Studies, delving into the complexities of health information behavior and its influence on immigrant communities in Nordic countries. Through advanced data analytics, mixed-method research, and digital information modeling, I navigated the intricate relationship between trust, cultural adaptation, and digital health literacy, forging a data-driven path to better understand marginalized communities.
I immersed myself in the field of Information Studies, delving into the complexities of health information behavior and its influence on immigrant communities in Nordic countries. Through advanced data analytics, mixed-method research, and digital information modeling, I navigated the intricate relationship between trust, cultural adaptation, and digital health literacy, forging a data-driven path to better understand marginalized communities.
I embarked on an intellectual journey into knowledge management, mastering the art of structuring, analyzing, and optimizing information flows in digital and healthcare contexts. With a focus on e-health and digital literacy, I explored how older adults navigate health information ecosystems, forging a connection between user behavior, technology, and healthcare accessibility
 Immersing myself in the intricate world of financial modeling and investment strategies, I developed expertise in risk assessment, capital markets, and asset pricing theories. Navigating the complexities of systematic and non-systematic risk, I cultivated a data-driven approach to financial decision-making, blending quantitative analysis with economic foresight to assess investment performance.
Immersing myself in the intricate world of financial modeling and investment strategies, I developed expertise in risk assessment, capital markets, and asset pricing theories. Navigating the complexities of systematic and non-systematic risk, I cultivated a data-driven approach to financial decision-making, blending quantitative analysis with economic foresight to assess investment performance.
 I delved deep into the fundamentals of accounting and taxation, mastering the principles of financial reporting, tax law, and auditing. Exploring the intricate balance between regulatory compliance and economic efficiency, I developed a strong analytical mindset, navigating the realms of corporate finance, fiscal policy, and strategic financial planning.
I delved deep into the fundamentals of accounting and taxation, mastering the principles of financial reporting, tax law, and auditing. Exploring the intricate balance between regulatory compliance and economic efficiency, I developed a strong analytical mindset, navigating the realms of corporate finance, fiscal policy, and strategic financial planning.
 As a Project Researcher at the Migration Institute of Finland and Åbo Akademi University, I conduct quantitative research for the Mobile Futures project, funded by the Research Council of Finland. My work focuses on analyzing European Social Survey (ESS) data using Python to examine how trust, values, and digital information encounters shape European managers' attitudes toward immigrants. Specifically, I contribute to:
As a Project Researcher at the Migration Institute of Finland and Åbo Akademi University, I conduct quantitative research for the Mobile Futures project, funded by the Research Council of Finland. My work focuses on analyzing European Social Survey (ESS) data using Python to examine how trust, values, and digital information encounters shape European managers' attitudes toward immigrants. Specifically, I contribute to:
I process, clean, and visualize large-scale datasets using Pandas, NumPy, and Matplotlib. Additionally, I apply advanced statistical techniques, including Multilevel Linear Regression, to analyze hierarchical data structures and uncover patterns in managers' trust and value systems. My research contributes to ongoing academic discussions, with findings under review in leading migration studies journals, supporting evidence-based policymaking on labor market inclusion and migration governance in Europe.
 This postdoctoral research project, funded by the Finnish Cultural Foundation, is scheduled to begin on March 1, 2027, at the Migration Institute of Finland. This project will explore how AI-driven services can enhance the labour market integration of international students in Finland, addressing key barriers such as language proficiency, discrimination in hiring, and lack of labour market knowledge. The study will be conducted in multiple phases, including meta-analysis, qualitative research with students and employers, and the development of an AI-powered employment framework.
This postdoctoral research project, funded by the Finnish Cultural Foundation, is scheduled to begin on March 1, 2027, at the Migration Institute of Finland. This project will explore how AI-driven services can enhance the labour market integration of international students in Finland, addressing key barriers such as language proficiency, discrimination in hiring, and lack of labour market knowledge. The study will be conducted in multiple phases, including meta-analysis, qualitative research with students and employers, and the development of an AI-powered employment framework.
 As a Doctoral Researcher at Åbo Akademi University, I investigate immigrants' health beliefs, healthcare needs, and the use of healthcare services across Finland, Sweden, and Norway. This research is part of my PhD study and is funded by the Finnish Cultural Foundation, Karl-Erik Henriksson Foundation, and Åbo Akademis Jubileumsfond. The project aims to provide evidence-based recommendations for healthcare providers, policymakers, and research institutions working with minority populations in the Nordic region.
As a Doctoral Researcher at Åbo Akademi University, I investigate immigrants' health beliefs, healthcare needs, and the use of healthcare services across Finland, Sweden, and Norway. This research is part of my PhD study and is funded by the Finnish Cultural Foundation, Karl-Erik Henriksson Foundation, and Åbo Akademis Jubileumsfond. The project aims to provide evidence-based recommendations for healthcare providers, policymakers, and research institutions working with minority populations in the Nordic region.
Specifically, I contribute to:
I design and implement quantitative and qualitative data collection strategies, ensuring methodological rigour in cross-country comparative research. Additionally, I analyse survey and interview data using advanced statistical and qualitative techniques to uncover patterns in health-seeking behaviour.
Findings from this research have been published in peer-reviewed journals such as Library & Information Science Research (Jufo 3) and Informaatiotutkimus (Jufo 1), contributing to academic discussions on immigrant health, cultural adaptation, and information-seeking behaviour. My work supports policymakers and healthcare organisations in developing inclusive, data-driven healthcare strategies for diverse immigrant populations in the Nordic region.
 As a Doctoral Researcher at Åbo Akademi University, I investigated health information-seeking behavior among Persian-speaking minorities in Finland during the COVID-19 pandemic. This research was part of my PhD study and was funded by the OTTO A. MALM FOUNDATION and KAKS (Municipal Sector Development Foundation). The project aimed to provide evidence-based insights into how non-native minorities accessed, evaluated, and utilized health information during a global health crisis, contributing to improved public health communication strategies.
As a Doctoral Researcher at Åbo Akademi University, I investigated health information-seeking behavior among Persian-speaking minorities in Finland during the COVID-19 pandemic. This research was part of my PhD study and was funded by the OTTO A. MALM FOUNDATION and KAKS (Municipal Sector Development Foundation). The project aimed to provide evidence-based insights into how non-native minorities accessed, evaluated, and utilized health information during a global health crisis, contributing to improved public health communication strategies.
Specifically, I contributed to:
I designed and implemented qualitative data collection strategies, ensuring methodological rigor in capturing immigrants' lived experiences during the pandemic. Additionally, I applied thematic analysis techniques to uncover patterns in health information-seeking behavior and identify key factors influencing trust, misinformation exposure, and health decision-making.
Findings from this research have been published in high-impact peer-reviewed journals, including Library & Information Science Research (Jufo 3) and Journal of Documentation (Jufo 3). These publications contribute to academic discussions on health communication, immigrant information behavior, and crisis response strategies. My work supports policymakers, healthcare providers, and public health institutions in developing inclusive, evidence-based approaches to healthcare communication for minority populations, particularly in times of crisis.

This project, led by Kim Holmberg and conducted from 2024 to 2026, investigates how mainstream media misrepresents scientific findings and how such misrepresentations influence public trust in science. As a Senior Researcher, I contribute to analysing media narratives, evaluating their alignment with original scientific content, and assessing public reactions.
 This project, running from 2024 to 2028 under the leadership of Kim Holmberg, explores how retracted scientific articles continue to shape public opinion, policy-making, and evidence-informed decisions. In my role as a Senior Researcher, I study the dissemination of unreliable science on social and mainstream media platforms and its consequences for public trust and health communication.
This project, running from 2024 to 2028 under the leadership of Kim Holmberg, explores how retracted scientific articles continue to shape public opinion, policy-making, and evidence-informed decisions. In my role as a Senior Researcher, I study the dissemination of unreliable science on social and mainstream media platforms and its consequences for public trust and health communication.
 Earned the Google Data Analytics Certificate, demonstrating proficiency in data analysis techniques, including data cleaning, visualization, and interpretation using tools like Excel, SQL, and R. This certification enhances my ability to derive actionable insights from complex datasets.
Earned the Google Data Analytics Certificate, demonstrating proficiency in data analysis techniques, including data cleaning, visualization, and interpretation using tools like Excel, SQL, and R. This certification enhances my ability to derive actionable insights from complex datasets.
 Completed the Intermediate Pandas Python Library for Data Science course, advancing my skills in data manipulation, analysis, and visualization using Pandas. Gained expertise in handling large datasets, performing grouping, merging, reshaping, and advanced indexing. Developed efficiency in time series analysis and data preprocessing for machine learning workflows.
Completed the Intermediate Pandas Python Library for Data Science course, advancing my skills in data manipulation, analysis, and visualization using Pandas. Gained expertise in handling large datasets, performing grouping, merging, reshaping, and advanced indexing. Developed efficiency in time series analysis and data preprocessing for machine learning workflows.
 Completed the Pandas Python Library for Beginners in Data Science course, gaining foundational skills in data manipulation and analysis using Python. Learned essential Pandas functions for reading, cleaning, filtering, and summarizing datasets. Developed a strong understanding of data structures like Series and DataFrames, preparing data for further analysis in machine learning and statistical modeling.
Completed the Pandas Python Library for Beginners in Data Science course, gaining foundational skills in data manipulation and analysis using Python. Learned essential Pandas functions for reading, cleaning, filtering, and summarizing datasets. Developed a strong understanding of data structures like Series and DataFrames, preparing data for further analysis in machine learning and statistical modeling.
 Completed an 18-hour hands-on course from the University of Washington with a grade of 95.79%, covering fundamental machine learning concepts. Developed expertise in regression, classification, clustering, retrieval, recommender systems, and deep learning. Applied these techniques to real-world case studies, including predicting house prices, sentiment analysis, and product recommendations. Gained proficiency in using Python for implementing machine learning models and evaluating their performance with relevant error metrics.
Completed an 18-hour hands-on course from the University of Washington with a grade of 95.79%, covering fundamental machine learning concepts. Developed expertise in regression, classification, clustering, retrieval, recommender systems, and deep learning. Applied these techniques to real-world case studies, including predicting house prices, sentiment analysis, and product recommendations. Gained proficiency in using Python for implementing machine learning models and evaluating their performance with relevant error metrics.
 Completed the MATLAB Onramp training, gaining foundational skills in MATLAB programming, data visualization, and mathematical computing. Developed expertise in handling matrices and arrays, writing scripts, debugging code, and performing basic numerical analysis. Acquired hands-on experience with MATLAB’s built-in functions for data manipulation and visualization.
Completed the MATLAB Onramp training, gaining foundational skills in MATLAB programming, data visualization, and mathematical computing. Developed expertise in handling matrices and arrays, writing scripts, debugging code, and performing basic numerical analysis. Acquired hands-on experience with MATLAB’s built-in functions for data manipulation and visualization.
 Completed NVivo Online Training (Blended Learning) with Alfasoft in collaboration with Åbo Akademi University. Acquired expertise in qualitative data analysis, including thematic coding, content analysis, and data visualization techniques. Developed skills in managing large textual datasets, analyzing qualitative responses, and deriving insights for academic and industry research
Completed NVivo Online Training (Blended Learning) with Alfasoft in collaboration with Åbo Akademi University. Acquired expertise in qualitative data analysis, including thematic coding, content analysis, and data visualization techniques. Developed skills in managing large textual datasets, analyzing qualitative responses, and deriving insights for academic and industry research
 Completed a comprehensive introduction to the Internet of Things (IoT), covering key concepts such as systems, information and networks, probability, game theory, and IoT applications. Gained insights into different types of data and their impact on device communication. Developed the ability to identify real-world IoT applications and perform basic system analysis.
Completed a comprehensive introduction to the Internet of Things (IoT), covering key concepts such as systems, information and networks, probability, game theory, and IoT applications. Gained insights into different types of data and their impact on device communication. Developed the ability to identify real-world IoT applications and perform basic system analysis.
 Gained expertise in creating advanced path models using SmartPLS, useful in both research and industry decision-making. Learned to analyze how attitudes and subjective norms impact behavioral change. Developed skills in running models across groups (e.g., gender-based analysis) and interpreting results to provide actionable recommendations.
Gained expertise in creating advanced path models using SmartPLS, useful in both research and industry decision-making. Learned to analyze how attitudes and subjective norms impact behavioral change. Developed skills in running models across groups (e.g., gender-based analysis) and interpreting results to provide actionable recommendations.
 Acquired hands-on experience in building path models using SmartPLS for data-driven decision-making in research and industry. Developed skills in uploading datasets, designing structural models, and executing Partial Least Squares Structural Equation Modeling (PLS-SEM). Gained proficiency in interpreting model outputs to derive meaningful insights and recommendations.
Acquired hands-on experience in building path models using SmartPLS for data-driven decision-making in research and industry. Developed skills in uploading datasets, designing structural models, and executing Partial Least Squares Structural Equation Modeling (PLS-SEM). Gained proficiency in interpreting model outputs to derive meaningful insights and recommendations.
Earned the Google Data Analytics Certificate, demonstrating proficiency in data analysis techniques, including data cleaning, visualization, and interpretation using tools like Excel, SQL, and R. This certification enhances my ability to derive actionable insights from complex datasets.
Completed the Intermediate Pandas Python Library for Data Science course, advancing my skills in data manipulation, analysis, and visualization using Pandas. Gained expertise in handling large datasets, performing grouping, merging, reshaping, and advanced indexing. Developed efficiency in time series analysis and data preprocessing for machine learning workflows.
Completed the Pandas Python Library for Beginners in Data Science course, gaining foundational skills in data manipulation and analysis using Python. Learned essential Pandas functions for reading, cleaning, filtering, and summarizing datasets. Developed a strong understanding of data structures like Series and DataFrames, preparing data for further analysis in machine learning and statistical modeling.
Completed an 18-hour hands-on course from the University of Washington with a grade of 95.79%, covering fundamental machine learning concepts. Developed expertise in regression, classification, clustering, retrieval, recommender systems, and deep learning. Applied these techniques to real-world case studies, including predicting house prices, sentiment analysis, and product recommendations. Gained proficiency in using Python for implementing machine learning models and evaluating their performance with relevant error metrics.
Completed the MATLAB Onramp training, gaining foundational skills in MATLAB programming, data visualization, and mathematical computing. Developed expertise in handling matrices and arrays, writing scripts, debugging code, and performing basic numerical analysis. Acquired hands-on experience with MATLAB’s built-in functions for data manipulation and visualization.
Completed NVivo Online Training (Blended Learning) with Alfasoft in collaboration with Åbo Akademi University. Acquired expertise in qualitative data analysis, including thematic coding, content analysis, and data visualization techniques. Developed skills in managing large textual datasets, analyzing qualitative responses, and deriving insights for academic and industry research
Completed a comprehensive introduction to the Internet of Things (IoT), covering key concepts such as systems, information and networks, probability, game theory, and IoT applications. Gained insights into different types of data and their impact on device communication. Developed the ability to identify real-world IoT applications and perform basic system analysis.
Gained expertise in creating advanced path models using SmartPLS, useful in both research and industry decision-making. Learned to analyze how attitudes and subjective norms impact behavioral change. Developed skills in running models across groups (e.g., gender-based analysis) and interpreting results to provide actionable recommendations.
Acquired hands-on experience in building path models using SmartPLS for data-driven decision-making in research and industry. Developed skills in uploading datasets, designing structural models, and executing Partial Least Squares Structural Equation Modeling (PLS-SEM). Gained proficiency in interpreting model outputs to derive meaningful insights and recommendations.

2025 Finnish Cultural Foundation, Two-year Post Doctoral Project Grant.
2024 Åbo Akademi University, Travel Grant for Conference Participation at NFF2024 (1200€).
2022 Åbo Akademis Jubileumsfond, Grant for research visit at University of Borås (4 months, 27,600 SEK).
2022 Åbo Akademi University, Travel Grant for research visit at OSLOMET (1 months, 1200€).
2022 Karl-Erik Henriksson Foundation, Grant for scientific research at OSLOMET (850€).
2022 Finnish Cultural Foundation, One-year doctoral thesis grant (12 months, 26,000€).
2021 KAKS (Municipal Sector Development Foundation), One-year doctoral thesis grant (12 months, 20,000€).
2020 Otto A. Malm Foundation, Six-month doctoral thesis grant (6 months, 13,000€).
 24/06/2024 Åbo Akademi University, Publication Bonuse (100€).
24/06/2024 Åbo Akademi University, Publication Bonuse (100€).
02/02/2024 Åbo Akademi University, Publication Bonuse (1000€).
31/10/2022 Åbo Akademi University, Publication Bonuse (267€).
30/06/2022 Åbo Akademi University, Publication Bonuse (800€).
17/06/2021 Åbo Akademi University, Publication Bonuse (634€).
 University of Borås, Sweden
University of Borås, Sweden
Research Visitor, Information Practices and Digital Cultures Group
1.9.2022- 15.12.2022
Skills: NVivo, Data Collection, Intercultural Communication, Qualitative & Quantitative Research, Mixed-Methods Design, Research Planning & Management, Data Analysis, Research Evaluation.
 Oslo Metropolitan University, Oslo
Oslo Metropolitan University, Oslo
Research Visitor, INFUSE Research Group
1.5.2022-1.6.2022
Skills: NVivo, Data Collection (Qualitative & Quantitative), Mixed-Methods Research, Research Design, Intercultural Communication, Planning & Evaluation.
 Since Augest 2025, I have been serving as a peer reviewer for Journal of Documentation. In this role, I critically assess submitted manuscripts, offer constructive feedback to authors, and help uphold the journal’s scholarly standards in the field of information science.
Since Augest 2025, I have been serving as a peer reviewer for Journal of Documentation. In this role, I critically assess submitted manuscripts, offer constructive feedback to authors, and help uphold the journal’s scholarly standards in the field of information science.

Since July 2025, I have been serving as a peer reviewer for Library and Information Science Research. In this role, I critically assess submitted manuscripts, offer constructive feedback to authors, and help uphold the journal’s scholarly standards in the field of Library and Information Science.
 Serving as an Academic Editor for PLOS ONE (PLOS) (Impact Factor: 3.7), I contribute to the peer review process by overseeing the evaluation of scholarly manuscripts, ensuring rigorous academic standards, and facilitating high-quality research dissemination. My role involves assessing submissions, coordinating peer reviews, and making editorial decisions to uphold the journal's commitment to open-access scientific publishing
Serving as an Academic Editor for PLOS ONE (PLOS) (Impact Factor: 3.7), I contribute to the peer review process by overseeing the evaluation of scholarly manuscripts, ensuring rigorous academic standards, and facilitating high-quality research dissemination. My role involves assessing submissions, coordinating peer reviews, and making editorial decisions to uphold the journal's commitment to open-access scientific publishing
 As an Article Editor for SAGE Open (SAGE Publications) (Impact Factor: 2.032), I contribute to the peer review and editorial process by evaluating manuscripts, coordinating reviews, and ensuring the publication of high-quality, interdisciplinary research. My role supports the journal's commitment to open-access publishing and scholarly excellence
As an Article Editor for SAGE Open (SAGE Publications) (Impact Factor: 2.032), I contribute to the peer review and editorial process by evaluating manuscripts, coordinating reviews, and ensuring the publication of high-quality, interdisciplinary research. My role supports the journal's commitment to open-access publishing and scholarly excellence
 Since Jun 2025, I have been serving as a peer reviewer for Social Sciences & Humanities Open. In this role, I critically evaluate submitted manuscripts, provide constructive feedback to authors, and contribute to maintaining the journal’s high scholarly standards in Social Sciences & Humanities.
Since Jun 2025, I have been serving as a peer reviewer for Social Sciences & Humanities Open. In this role, I critically evaluate submitted manuscripts, provide constructive feedback to authors, and contribute to maintaining the journal’s high scholarly standards in Social Sciences & Humanities.
 As a peer reviewer for the Journal of International Migration and Integration (Impact Factor: 1.3), I critically assess research manuscripts, provide constructive feedback to authors, and contribute to maintaining the journal’s high academic and methodological standards in migration and integration studies.
As a peer reviewer for the Journal of International Migration and Integration (Impact Factor: 1.3), I critically assess research manuscripts, provide constructive feedback to authors, and contribute to maintaining the journal’s high academic and methodological standards in migration and integration studies.
 Since 2022, I have served as a peer reviewer for the Journal of Public Health (Oxford University Press, Impact Factor: 5.058). In this role, I critically evaluate submitted manuscripts, provide constructive feedback to authors, and contribute to maintaining the journal’s high scholarly standards in public health research.
Since 2022, I have served as a peer reviewer for the Journal of Public Health (Oxford University Press, Impact Factor: 5.058). In this role, I critically evaluate submitted manuscripts, provide constructive feedback to authors, and contribute to maintaining the journal’s high scholarly standards in public health research.
 As a peer reviewer for BMC Public Health (BioMed Central) (Impact Factor: 4.5), I critically assess research manuscripts, provide constructive feedback to authors, and contribute to maintaining the journal’s high academic and methodological standards in public health research.
As a peer reviewer for BMC Public Health (BioMed Central) (Impact Factor: 4.5), I critically assess research manuscripts, provide constructive feedback to authors, and contribute to maintaining the journal’s high academic and methodological standards in public health research.
 As a peer reviewer for Scientific Reports (Nature) (Impact Factor: 3.8), I evaluate submitted manuscripts, provide constructive feedback, and ensure the publication of high-quality research across diverse scientific disciplines.
As a peer reviewer for Scientific Reports (Nature) (Impact Factor: 3.8), I evaluate submitted manuscripts, provide constructive feedback, and ensure the publication of high-quality research across diverse scientific disciplines.
 As a peer reviewer for Health Policy (Elsevier) (Impact Factor: 3.3), I critically evaluate research manuscripts, provide constructive feedback to authors, and contribute to maintaining the journal’s high academic standards in health policy and healthcare system research.
As a peer reviewer for Health Policy (Elsevier) (Impact Factor: 3.3), I critically evaluate research manuscripts, provide constructive feedback to authors, and contribute to maintaining the journal’s high academic standards in health policy and healthcare system research.
 As a peer reviewer for Archives of Public Health (BioMed Central) (Impact Factor: 3.3), I evaluate research manuscripts, provide constructive feedback, and contribute to ensuring the publication of high-quality studies in public health. My role supports the journal’s mission of advancing evidence-based research and public health policy.
As a peer reviewer for Archives of Public Health (BioMed Central) (Impact Factor: 3.3), I evaluate research manuscripts, provide constructive feedback, and contribute to ensuring the publication of high-quality studies in public health. My role supports the journal’s mission of advancing evidence-based research and public health policy.
 Since 2023, I have served as a peer reviewer for the International Journal of Public Health (Springer Nature) (Impact Factor: 2.6). In this capacity, I critically assess submitted manuscripts, offer constructive feedback to authors, and contribute to upholding the journal’s rigorous academic standards in public health research
Since 2023, I have served as a peer reviewer for the International Journal of Public Health (Springer Nature) (Impact Factor: 2.6). In this capacity, I critically assess submitted manuscripts, offer constructive feedback to authors, and contribute to upholding the journal’s rigorous academic standards in public health research
 Since 2021, I have served as a peer reviewer for Europen Management Review (Wiley, Impact Factor: 2.534). In this role, I critically evaluate submitted manuscripts, provide constructive feedback to authors, and contribute to maintaining the journal’s high scholarly standards in management research.
Since 2021, I have served as a peer reviewer for Europen Management Review (Wiley, Impact Factor: 2.534). In this role, I critically evaluate submitted manuscripts, provide constructive feedback to authors, and contribute to maintaining the journal’s high scholarly standards in management research.
 Since 2022, I have served as a peer reviewer for Social Work in Public Health (Taylor & Francis) (Impact Factor: 2.313).
Since 2022, I have served as a peer reviewer for Social Work in Public Health (Taylor & Francis) (Impact Factor: 2.313).
 Since 2024, I have served as a peer reviewer for Public Health Nursing (Springer Nature) (Impact Factor: 2.1). In this role, I critically evaluate submitted manuscripts, provide constructive feedback to authors, and contribute to upholding the journal’s high scholarly standards in public health and nursing research.
Since 2024, I have served as a peer reviewer for Public Health Nursing (Springer Nature) (Impact Factor: 2.1). In this role, I critically evaluate submitted manuscripts, provide constructive feedback to authors, and contribute to upholding the journal’s high scholarly standards in public health and nursing research.
 Since 2023, I have served as a peer reviewer for Information Systems Management (Taylor & Francis) (Impact Factor: 2.098). In this role, I critically evaluate submitted manuscripts, provide constructive feedback to authors, and contribute to maintaining the journal’s high scholarly standards in information systems and management research.
Since 2023, I have served as a peer reviewer for Information Systems Management (Taylor & Francis) (Impact Factor: 2.098). In this role, I critically evaluate submitted manuscripts, provide constructive feedback to authors, and contribute to maintaining the journal’s high scholarly standards in information systems and management research.
 Since 2023, I have served as a peer reviewer for International Migration (Wiley, Impact Factor: 1.946). In this role, I critically evaluate submitted manuscripts, provide constructive feedback to authors, and contribute to maintaining the journal’s high scholarly standards in information systems and management research.
Since 2023, I have served as a peer reviewer for International Migration (Wiley, Impact Factor: 1.946). In this role, I critically evaluate submitted manuscripts, provide constructive feedback to authors, and contribute to maintaining the journal’s high scholarly standards in information systems and management research.
 Since 2011, I have served as a peer reviewer for Applied Economics (Taylor & Francis) (Impact Factor: 1.835). In this role, I critically assess submitted manuscripts, provide constructive feedback to authors, and contribute to maintaining the journal’s rigorous academic standards in economic research and applied economic analysis.
Since 2011, I have served as a peer reviewer for Applied Economics (Taylor & Francis) (Impact Factor: 1.835). In this role, I critically assess submitted manuscripts, provide constructive feedback to authors, and contribute to maintaining the journal’s rigorous academic standards in economic research and applied economic analysis.
 Since 2023, I have served as a peer reviewer for Cogent Social Sciences (Taylor & Francis, Impact Factor: 1.5).
Since 2023, I have served as a peer reviewer for Cogent Social Sciences (Taylor & Francis, Impact Factor: 1.5).
 Since 2024, I have served as a peer reviewer for Information Research (published by the University of Borås, Sweden). In this role, I critically evaluate submitted manuscripts, provide constructive feedback to authors, and contribute to maintaining the journal’s high scholarly standards in information science and research.
Since 2024, I have served as a peer reviewer for Information Research (published by the University of Borås, Sweden). In this role, I critically evaluate submitted manuscripts, provide constructive feedback to authors, and contribute to maintaining the journal’s high scholarly standards in information science and research.
 In 2022, I served as an Associate Reviewer for InSITE 2022: Exploring Virtual Connections as Mechanisms for Teaching and Research, part of the Informing Science + IT Education Conferences organized by the Informing Science Institute. In this role, I evaluated submitted conference papers, provided constructive feedback to authors, and contributed to maintaining the academic rigor of the conference proceedings.
In 2022, I served as an Associate Reviewer for InSITE 2022: Exploring Virtual Connections as Mechanisms for Teaching and Research, part of the Informing Science + IT Education Conferences organized by the Informing Science Institute. In this role, I evaluated submitted conference papers, provided constructive feedback to authors, and contributed to maintaining the academic rigor of the conference proceedings.
 In 2018, I served as a Co-Editor for the WIS Conference: Well-Being in the Information Society – Fighting Inequalities, held in Turku, Finland, from May to August 2018. In this role, I contributed to the editorial process, ensuring the quality and coherence of the conference proceedings while facilitating scholarly discussions on well-being and information society challenges.
In 2018, I served as a Co-Editor for the WIS Conference: Well-Being in the Information Society – Fighting Inequalities, held in Turku, Finland, from May to August 2018. In this role, I contributed to the editorial process, ensuring the quality and coherence of the conference proceedings while facilitating scholarly discussions on well-being and information society challenges.
 I was featured in the Migration Institute of Finland’s Newsletter (December 2023) as part of the 'New Institute Members' section, highlighting my academic contributions and research focus.
I was featured in the Migration Institute of Finland’s Newsletter (December 2023) as part of the 'New Institute Members' section, highlighting my academic contributions and research focus.
 I was interviewed by Polemiikki magazine, a journal published by The Foundation for Municipal Development (KAKS), about my doctoral research project on immigrants’ health-seeking behavior. The interview was published as 'Tavoittaako terveydenhuolto kasvavan maahanmuuttajaväestön?' in Issue 1/2021.
I was interviewed by Polemiikki magazine, a journal published by The Foundation for Municipal Development (KAKS), about my doctoral research project on immigrants’ health-seeking behavior. The interview was published as 'Tavoittaako terveydenhuolto kasvavan maahanmuuttajaväestön?' in Issue 1/2021.
Attending the ECSR 2026 Conference in Dublin was an important opportunity for me to reflect on current debates in social stratification research. One of the strongest moments of the conference was the keynote lecture by Professor Moris Triventi from the University of Milan, titled “Social Stratification Research in the Age of Big Data: Challenges and Opportunities Ahead".
The keynote was not simply about big data. It was about what big data can do for social stratification research when it is used carefully, theoretically, and cumulatively. Professor Triventi’s central message was clear: big data and big models are not enough by themselves. They become valuable only when they are connected to strong theory, shared questions, careful measurement, transparent inference, and a serious scientific programme.

Before moving into the main argument, Professor Triventi used a background slide with a comic-style visual that placed the talk in a more personal and reflective frame. I found this opening effective because it reminded the audience that the keynote was not only about methods or data. It was also about how a research field thinks about its past, present, and future.
The slide visually connected Dublin, Milan, and the work of social stratification research. It created a lighter moment at the beginning of the keynote, but it also introduced a serious question: how should scholars reflect on what the field has already achieved while preparing for the methodological and substantive challenges ahead?
This background helped set the tone for the rest of the lecture. The keynote was forward-looking, but it was not detached from the history of the field. Professor Triventi’s argument was that social stratification research should engage with new data and methods without losing the theoretical, empirical, and cumulative traditions that have made the field strong.

After the background slide, Professor Triventi presented the roadmap for the keynote. This outline was useful because it showed that the talk was not organised around big data alone. Instead, it moved through a broader intellectual sequence: what the field has already learned, what has changed, what risks accompany the expansion of data and methods, where the field should go, and why these questions matter.
I found this structure helpful because it framed the keynote as both a review and an agenda-setting lecture. The talk first returned to the foundations of social stratification research, then considered how new data and methods are changing the field, and finally asked how stratification research can remain theoretically grounded, empirically rigorous, and relevant to public problems.
The roadmap also made clear that Professor Triventi was not arguing for methodological novelty for its own sake. The keynote was about how new tools can strengthen the field only when they are connected to shared questions, cumulative knowledge, and better explanations of inequality.

Before moving into the main argument, Professor Triventi also clarified what the keynote would not cover. He explicitly placed artificial intelligence, data privacy, ethics, institutional development, and relations with policymakers outside the main scope of the talk.
I found this clarification useful because it narrowed the lecture in a disciplined way. In a keynote about big data, it would have been easy to move into broad debates about AI, governance, privacy, or institutional reform. Instead, Professor Triventi focused on a more specific question: how can new data and methods strengthen social stratification research as a scientific field?
This helped the audience understand that the talk was not about every possible implication of big data. It was about the internal scientific programme of stratification research: its questions, concepts, methods, risks, and opportunities.

The talk then placed social stratification research within the wider transformation of the social sciences. Researchers now have access to larger datasets, administrative records, longitudinal data, social media data, mobile phone data, satellite data, and increasingly powerful computational methods. These tools allow researchers to study inequalities in ways that were not possible before.
Professor Triventi showed examples of studies using millions of observations and large-scale computational approaches. These examples demonstrated the scale of contemporary empirical research. However, he did not present big data as a magic solution. Instead, he warned that larger datasets and more complex models do not automatically produce better social science.

This was one of the most important points of the keynote. The value of big data depends on the questions we ask with it. Without clear concepts and theory, big data can produce impressive-looking results without strong sociological meaning.
A particularly useful part of the keynote was the contrast between two positions.
On one side is the computational enthusiast. This position emphasises data mining, algorithms, prediction, scalability, pattern detection, and computational performance. It brings important strengths, especially when researchers need to detect complex patterns or work with large and heterogeneous datasets. But it also carries risks: weak theoretical grounding, unclear constructs, and black-box explanations.
On the other side is the traditional stratification researcher. This position emphasises theory, hypotheses, mechanisms, causal interpretation, social meaning, and cumulative knowledge. It provides the conceptual backbone of the field. But it can also become too restrictive if it ignores complexity, heterogeneity, and the opportunities offered by new data and methods.

The keynote did not argue that one position should replace the other. Instead, it called for integration. Computational methods can strengthen social stratification research, but only when they are embedded in theory, clear concepts, and disciplined research designs.
In this sense, the keynote offered a constructive middle position. It did not reject computational methods, nor did it abandon traditional sociological explanation. It asked how the two can be combined in a more rigorous research programme.
Professor Triventi defined social stratification research as the study of how advantages and disadvantages are structured, reproduced, and transmitted across individuals, groups, and generations through systems of unequal life chances.
This definition is useful because it reminds us that stratification is not only about income, education, class, or occupation separately. It is about how different forms of advantage and disadvantage are connected across the life course and across generations.

The traditional focus of the field has often been the relation between social origin, education, and destination. This classic framework remains important because family background continues to shape educational opportunities, and education continues to shape later life chances. But the keynote also showed that the field has expanded far beyond this model.
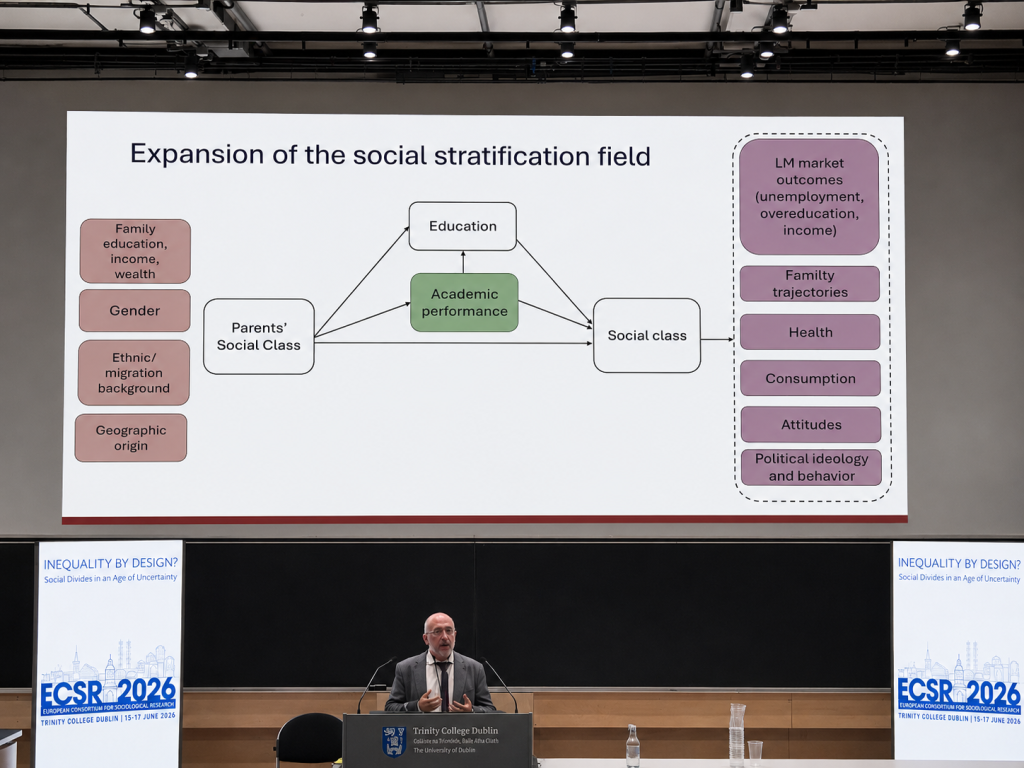
Professor Triventi’s slide on the expansion of the field made this shift very clear. The traditional core of stratification research remains important: parents’ social class shapes education and academic performance, and these in turn shape later social class. But the field now studies a much wider set of origins and outcomes.
On the origin side, stratification research increasingly examines family education, income, wealth, gender, ethnic and migration background, and geographic origin. On the outcome side, it now extends beyond social class to labour-market outcomes, family trajectories, health, consumption, attitudes, and political ideology and behaviour.
I found this slide useful because it showed both continuity and change. The field has not abandoned its classic questions about social origin, education, and destination. Instead, it has expanded those questions into a broader research agenda about how multiple forms of advantage and disadvantage are connected across the life course.
The expansion of the field is important. Social stratification research now examines gender, migration background, ethnicity, geographic origin, health, consumption, attitudes, political behaviour, and many other outcomes. This broader scope creates exciting possibilities, but it also requires stronger conceptual organisation. Without shared questions and comparable measures, an expanding field can easily become fragmented.
One of the strengths of the keynote was that it did not treat social stratification research as a field starting from zero. Professor Triventi reminded the audience that the field has already accumulated important empirical knowledge.
We know that occupational hierarchies and mobility patterns show considerable stability across countries and over time. We know that education remains a major channel of both upward mobility and intergenerational reproduction. We know that inequalities persist beyond education, because social origin continues to shape occupational rewards even after educational attainment is considered. We also know that educational institutions matter, including tracking systems, school structures, and institutional arrangements.

This part of the keynote was important because it showed the value of cumulative research. The field has already built a strong foundation. The challenge now is to connect new data and methods to that foundation rather than letting the field fragment into disconnected studies.
The message was not that previous stratification research is obsolete. The opposite was true. Professor Triventi’s argument was that the field should use new data and methods to extend and refine existing knowledge, not to forget it.
One of the strongest messages of the keynote was that the real transformation is not simply about having more data. What matters is what new data allow researchers to observe.
New data can offer temporal depth, allowing researchers to study trajectories, transitions, and cumulative processes over time. They can offer contextual precision, allowing researchers to examine local settings, schools, regions, and institutions in more detail. They can offer relational embeddedness, linking individuals to families, peers, teachers, institutions, and networks. They can also offer analytical flexibility, allowing researchers to combine description, causal inference, and prediction.
This point is essential. Big data should not only make old models larger. It should help researchers ask better questions about inequality.
Professor Triventi also showed that improved data and methods allow researchers to study inequalities that are distributional, intersecting, dynamic, and spatially embedded. This means moving beyond average outcomes, taking seriously how multiple social characteristics combine, following inequalities across the life course, and recognising that local contexts shape opportunity.
For me, this was one of the most valuable parts of the keynote. It showed that new methods are not just technical instruments. They can change the kinds of sociological questions we are able to ask. They allow us to see inequality not only as a static gap but also as a dynamic, contextual, and relational process.
Professor Triventi also discussed different types of data infrastructures that can enrich inequality research. These included multi-actor data, multilevel data, longitudinal data, administrative data, text data, social media data, mobile phone data, and satellite data.
Each type of data offers something different. Multi-actor data can connect students, parents, teachers, peers, and institutions. Multilevel data can locate individuals within schools, neighbourhoods, regions, and countries. Longitudinal data can follow life-course trajectories. Administrative data can provide broad coverage from public and institutional systems. Text and social media data can capture communication, attitudes, and digital traces.

At the same time, no data source is perfect. Survey data often contain rich concepts, but they may face declining response rates. Social media data can be large-scale and timely, but they are affected by selective participation and platform bias. Administrative data can be broad and complete, but they may include fewer theoretically meaningful variables.
This is why data triangulation matters. Stronger research often comes from combining different sources, not from assuming that one source can answer every question.
The keynote also identified risks that come with the expansion of social stratification research. One risk is fragmentation. As the field expands across topics, methods, and data sources, researchers may lose shared questions and common concepts.
Another risk is data quality and representativeness. Large datasets are not automatically good datasets. They may be incomplete, biased, or poorly aligned with the concepts researchers want to study.
A third risk is data-driven research replacing question-driven research. When research begins from available data rather than theoretically meaningful questions, the agenda can become shaped by convenience.
A fourth risk is description without explanation. Description is necessary, but it is not enough. Researchers also need theory and mechanisms to explain why inequalities emerge and how they might be reduced.

The slide on the challenges of an expanding field brought these risks together clearly. Professor Triventi identified four dangers that come with new data and new methods: fragmentation of the field, problems of data quality and representativeness, data-driven rather than question-driven research, and description without explanation.
What I found especially important was that the slide also pointed toward possible responses. Fragmentation requires shared questions. Data quality problems require triangulation. Data-driven research requires theory-driven designs. Description without explanation requires integrated analytical tools that connect micro and macro mechanisms.
This framing made the keynote more interesting for me. The problem is not that the field is expanding. Expansion is necessary and productive. The problem is that expansion can weaken cumulative knowledge if it is not organised by common questions, robust concepts, and explanatory aims.

After discussing the risks of an expanding field, Professor Triventi presented a broader framework for developing a rigorous and cumulative social stratification field. The slide organised the agenda around six pillars: theory; data triangulation, measurement, integrated analytical tools, evidence synthesis and reproducibility; and policy relevance.
I found this slide especially important because it connected many parts of the keynote into one integrated research programme. The point was not simply that the field needs better data or more advanced methods. It needs a structure that links theory, measurement, evidence, explanation, prediction, and policy relevance.
The six pillars also clarified how cumulative knowledge can be built. Theory, data triangulation, and measurement provide the foundations. Integrated analytical tools then help generate stronger evidence through description, causal inference, and prediction. Evidence synthesis and reproducibility allow findings to accumulate and be validated. Policy relevance connects scientific knowledge back to social problems and public interventions.
For me, this was one of the clearest summaries of the keynote’s main argument: social stratification research can benefit from big data, but only if these tools are embedded in a coherent scientific programme.
One of Professor Triventi’s central proposals was that social stratification research should rebuild cumulative knowledge around shared questions. These questions can help organise the field across different topics, datasets, and methods.
The core questions are 'Who gets what?' Through which mechanisms? Under which conditions? With what intergenerational consequences? And what can reduce inequality?
These questions are simple, but they are powerful. They can be applied to education, health, labour markets, migration, class, gender, and many other areas. They also help connect descriptive, explanatory, and policy-orientated research.
For example, in education, we might ask why children from advantaged families achieve more. In health, we might ask why disadvantaged groups have worse health and shorter lives. The specific mechanisms differ, but the structure of inquiry remains comparable.
For me, this was one of the most useful parts of the keynote. A field becomes cumulative not only by producing more studies but also by organising studies around questions that can speak to each other.

One of the most useful sections of the keynote focused on theory. Professor Triventi argued that empirical research should continue to be embedded in solid theoretical work.
Good theory should go beyond common sense. It should challenge taken-for-granted assumptions and reveal what is not obvious. It should avoid sterile overcomplication. It should specify mechanisms, generate testable propositions, clarify empirical implications, and specify scope conditions.

This was a powerful reminder that theory is not decoration. Theory should guide the whole research design. It should shape the research question, the concepts, the measurement strategy, the interpretation of results, and the limits of the claim.
Good theory does not just explain the past. It guides inquiry, structures evidence, and helps findings travel beyond one case.
Professor Triventi also emphasised data triangulation as a major opportunity for the field. This point became especially clear in the slide comparing survey data, social media data, and administrative data.
Survey data are strong because they contain rich concepts and carefully designed questions, but they may suffer from declining response rates and limited territorial detail. Social media data are large-scale and timely, but they raise problems of selective participation and platform bias. Administrative data often provide broad coverage and completeness, but they may contain fewer theoretically meaningful variables.
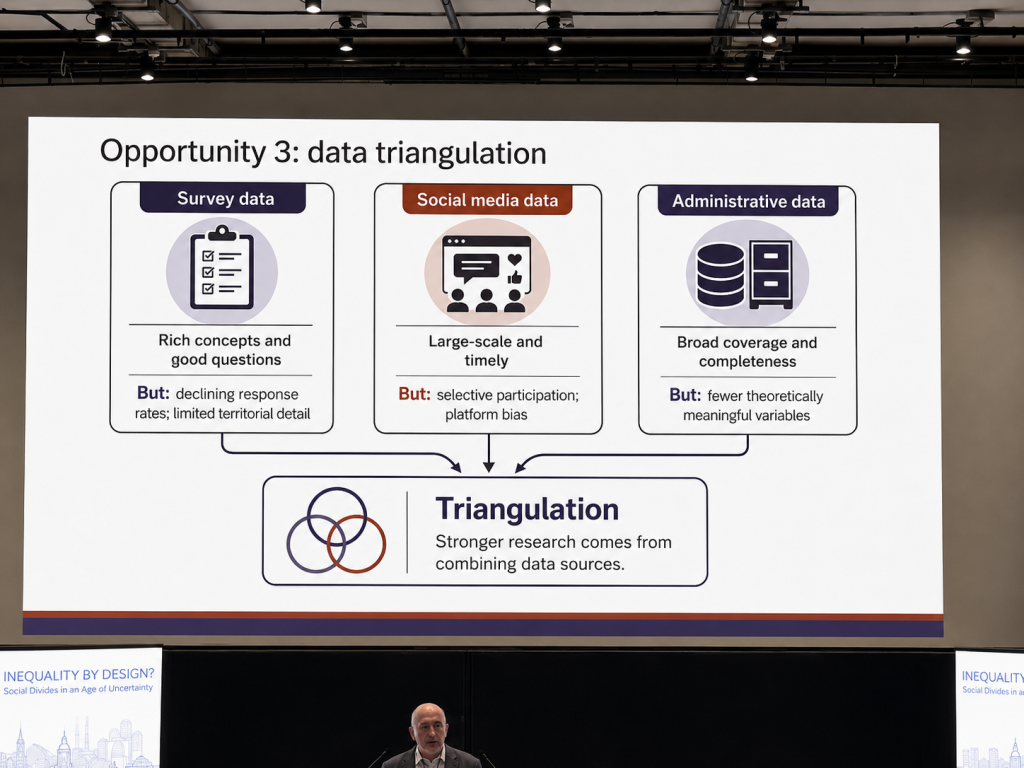
The conclusion was not that one type of data should replace the others. Stronger research comes from combining data sources carefully. Triangulation matters because different data sources can compensate for each other’s weaknesses and provide a fuller picture of inequality.
This was a useful corrective to simplistic claims about big data. A large administrative dataset may offer coverage but not always meaning. A survey may offer meaning, but not always scale. Social media data may offer timeliness, but not always representativeness. The strongest research designs often combine these strengths while being transparent about their limitations.
Another opportunity Professor Triventi emphasised was synthesis and reproducibility. This part of the keynote connected strongly with the idea of cumulative knowledge. More data become more useful only when results are comparable, reproducible, replicable, and synthesizable.
The slide identified four elements: shared indicators, reproducibility, replicability, and synthesis. Shared indicators allow researchers to compare concepts and measures across studies. Reproducibility means that the same data and code should lead to the same result. Replicability means that similar findings should appear in new data or settings when the underlying relationship is robust. Synthesis means building systematic reviews and meta-analyses that identify robust patterns, boundary conditions, and research gaps.
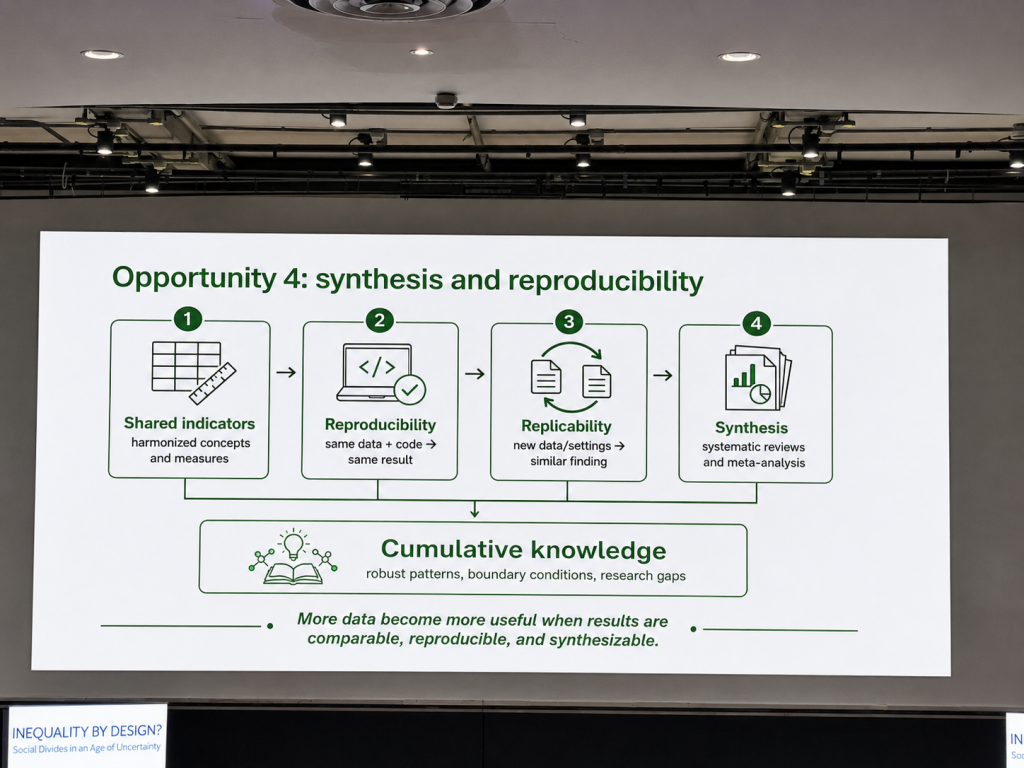
For me, this was one of the most important methodological messages of the keynote. A field does not become cumulative simply because it produces more studies. It becomes cumulative when studies can speak to one another. That requires comparable concepts, transparent workflows, shared measures, and a willingness to build knowledge beyond individual papers.
Another important argument in the keynote was that description, causal inference, and prediction should not be treated as competing approaches. They are three complementary analytical tasks.
Description remains indispensable because it forces researchers to document patterns carefully. It helps identify gradients, map variation, document new forms of inequality, and locate where disparities are greatest.
Causal inference disciplines explanation by asking what would happen under alternative conditions. It forces researchers to specify the causal question, the estimand, the research design, and the assumptions.
Prediction disciplines explanation by asking whether our explanations generate expectations beyond the observed case. It helps distinguish signals from overfitting and well-grounded explanations from post-hoc rationalisation.
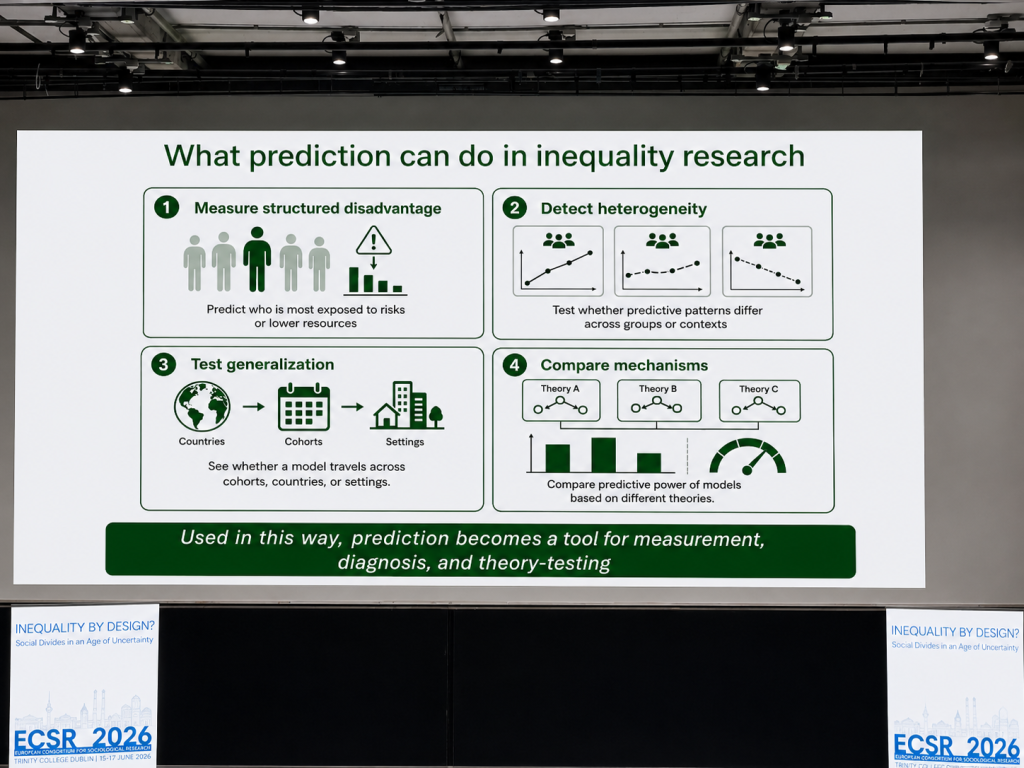
Professor Triventi’s slide on prediction made this point more concrete. Prediction was not presented as a replacement for explanation. Instead, it was presented as a tool for measurement, diagnosis, and theory-testing.
Prediction can help researchers measure structured disadvantage by identifying who is most exposed to risks or lower chances. It can also help detect heterogeneity by showing whether predictive patterns differ across groups or contexts. It can test generalisation by asking whether a model travels across countries, cohorts, or settings. Finally, it can compare mechanisms by assessing the predictive power of models based on different theoretical explanations.
I found this framing useful because it avoids a false opposition between prediction and explanation. Used carefully, prediction can discipline explanation. It asks whether our theoretical claims produce expectations that hold beyond the original case.
This integrated view was one of my main takeaways. The description tells us where inequality is and how large it is. Causal inference asks why it emerges and what might change it. Prediction asks whether an explanation travels beyond the original case. Together, these tasks can produce stronger and more credible inequality research.

This integrated view was one of my main takeaways. The description tells us where inequality is and how large it is. Causal inference asks why it emerges and what might change it. Prediction asks whether an explanation travels beyond the original case. Together, these tasks can produce stronger and more credible inequality research.
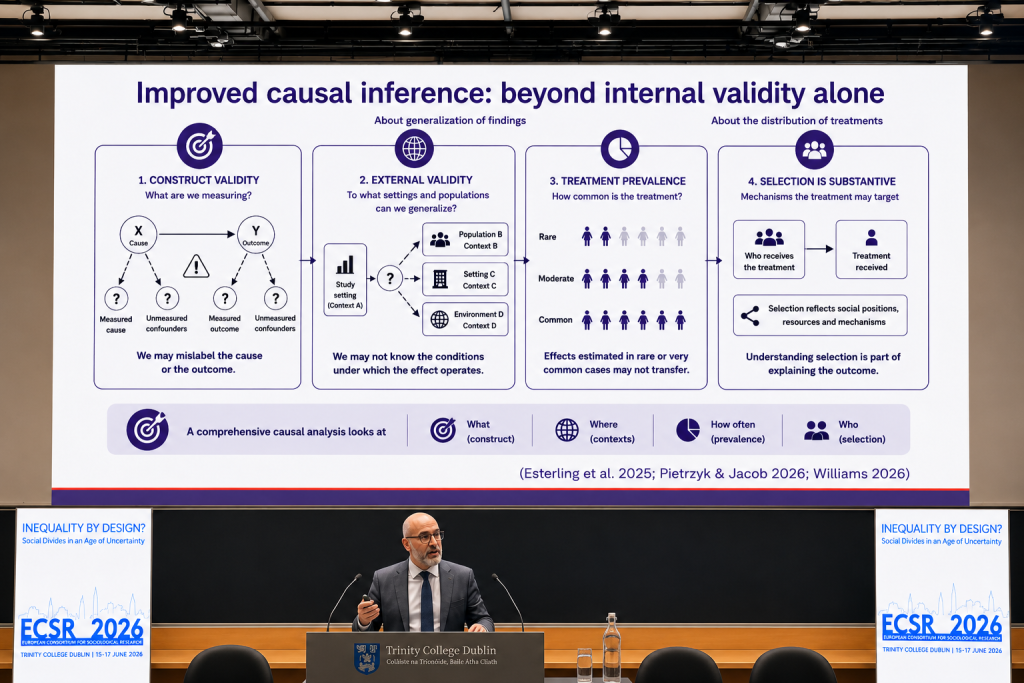
A particularly important methodological point concerned causal inference. Professor Triventi argued that improved causal inference should go beyond internal validity alone. It should also pay attention to construct validity, external validity, treatment prevalence, and selection.
Construct validity asks what researchers are actually measuring. External validity asks to what settings and populations findings can be generalised. Treatment prevalence asks how common the treatment or intervention is. Selection asks who receives the treatment and why.

This was important because it presented causal inference as more than a technical procedure. It is also a substantive sociological task. Understanding selection is part of understanding inequality. Who receives an intervention, who is excluded from it, and why those patterns emerge are not secondary details. They are part of the explanation.
The keynote also raised the question of how social stratification research can inform policy. Professor Triventi was careful here. He did not suggest that every study should end with simple policy advice. Instead, he argued that stratification research can contribute to policy by explaining mechanisms, defining concepts and indicators, identifying contextual enablers and blockers, estimating policy effects, detecting heterogeneous and unintended effects, and improving policy design.

This distinction matters. Stratification research is often very good at diagnosing inequality. It can show where inequality exists, how large it is, and which groups are affected. But the harder task is identifying feasible levers for reducing inequality. To do that, researchers need to connect diagnosis with mechanisms and intervention.
One of the strongest messages here was that policy relevance does not mean making quick recommendations. It means producing knowledge that can explain mechanisms, identify conditions, assess effects, and improve the design of interventions.
The keynote concluded with a clear agenda for the future of social stratification research.
The field should keep theory and mechanisms central. It should move toward estimand-driven, transparent, and robust inference. It should triangulate across methods and data sources. It should build a cumulative scientific programme. It should reconnect diagnosis with intervention.
For me, the keynote’s main message was that the future of social stratification research is not simply about bigger data or more advanced models. It is about building a more rigorous, theory-driven, and cumulative science of inequality.
The best research will not necessarily be the research with the largest dataset or the most complex method. It will be the research that asks important questions, measures concepts carefully, explains mechanisms, tests claims transparently, and contributes to knowledge that matters.
As a participant at ECSR 2026, I found this keynote intellectually rich and very relevant to current debates in sociology and inequality research. It reminded me that methodological innovation should not move us away from the core sociological questions. Instead, new data and methods should help us ask those questions better. The keynote also encouraged me to reflect on my own research practice. Am I asking questions that connect to a wider cumulative agenda? Are my concepts clear? Are my analytical choices transparent? Do my findings contribute to broader knowledge about inequality?
That, for me, was the value of Professor Triventi’s keynote. It did not simply celebrate big data. It asked what kind of scientific field we want to build with it. The answer, as I understood it, is a field that is open to new data and methods but not driven by them alone. A field that values description but does not stop at description. A field that uses causal inference and prediction but keeps theory and mechanisms at the centre. A field that diagnoses inequality but also asks how inequality might be reduced. That is a challenging agenda, but also an important one.
#ECSR2026 #SocialStratification #InequalityResearch #BigData #Sociology #SocialMobility #EducationInequality #ResearchMethods #CausalInference #DataTriangulation #AcademicConference #DublinConference #ComputationalSocialScience #EvidenceBasedPolicy #TheoryAndMethods #CumulativeKnowledge

I came across this image on LinkedIn, and it really made me pause and reflect.
As someone involved in research and teaching for many years, I strongly resonate with this message. AI is a powerful tool and will continue to shape the future of education — but it cannot replace the human essence of teaching.
Teaching has never been just about delivering information. It’s about connection — recognising when a student is struggling, offering the right support at the right time, and building trust that allows real learning to happen. It requires emotional intelligence, patience, and empathy.
What stood out to me most is the idea of teachers as role models. Beyond knowledge, we help shape how students think, grow, and see themselves. That influence comes from human interaction, not algorithms.
AI can enhance education, but it cannot replace the “heart” that teachers bring into the classroom.
I believe human connection will always remain at the core of meaningful education.
🎉 My new study is now published!
Everyday integration in Nordic welfare societies often hinges on something deceptively simple: access to clear, reliable, and usable information. From understanding healthcare systems to navigating the labour market, education, and social life, immigrants’ sense of belonging is shaped through everyday information encounters. This insight motivated my newly published article in Library & Information Science Research:
“Belonging through information: Mapping immigrant integration needs in Nordic societies”
🔗 https://doi.org/10.1016/j.lisr.2026.101400
The article is part of Mobile Futures - Research Consortium and was carried out in collaboration with Migration Institute of Finland & Åbo Akademi University.
📊 Conceptual focus of the study
The article maps immigrant integration through five interconnected dimensions, placing belonging at the centre and showing how information needs cut across all areas of everyday life:
1. Social integration – information about social networks, community activities, family support, childcare services, volunteering, and peer support.
2. Health integration – information on how healthcare systems work in practice, public vs. private services, entitlements, interpreters, mental health support, and medical communication.
3. Labour market integration – information about recognition of foreign qualifications, job-search practices, labour laws, workplace rights, and professional networks.
4. Cultural integration – information on local norms and customs, cultural events, community centres, media, and opportunities to express and maintain one’s own cultural traditions.
5. Educational integration – information about language learning, the education system, student services, scholarships, and educational and career pathways for both adults and children.
Based on semi-structured interviews with 54 first-generation immigrants in Finland, Sweden, and Norway, the findings show that integration challenges are not only about policies or services, but about whether information is understandable, accessible in familiar languages, and actionable in everyday situations. When institutional information is fragmented or unclear, people rely heavily on informal networks—often at the cost of confidence, wellbeing, and a sense of belonging.
📄 Read the article:
#ImmigrantIntegration #InformationBehaviour #Belonging #NordicCountries #LibraryAndInformationScience #QualitativeResearch #MigrationStudies #MobileFutures #ÅboAkademi #MigrationInstituteOfFinland #Finland #Sweden #Norway #HamedAhmadinia
I'm excited to share that I have officially completed the Practical Teacher Training (IPTE, 60 ECTS) program at Häme University of Applied Sciences (HAMK), Finland! 🎉
As part of this journey, I designed and delivered an 8-week university course titled
"Python for Data Analytics & Statistics" at Metropolia University of Applied Sciences.
This experience allowed me to merge educational theory with hands-on teaching, while applying student-centred, inclusive, and feedback-rich learning approaches in a real classroom setting.
📘 You can now read my full Learning Diary, documenting the full process from planning to outcomes:
🔗 https://lnkd.in/dkAwXYiH
💬 Special Thanks
This achievement wouldn’t have been possible without the support of:
Janne Salonen, my supervising teacher at Metropolia University of Applied Sciences, whose guidance, feedback, and encouragement were instrumental throughout my teaching journey.
Vesa Parkkonen, my tutor teacher at HAMK, for his thoughtful mentoring and for bridging the connection between pedagogical theory and practical implementation.
Your belief in my work made this learning experience not only successful but deeply meaningful. 🙏
👨🏫 What This Means
With this milestone, I am now a certified teacher in the Finnish higher education system. I’ve gained first-hand experience in course design, student engagement, and digital pedagogy—with practical tools like Jupyter, GitHub, and Kahoot integrated into my curriculum.
Whether in academia or industry education, I’m now even more prepared to contribute to impactful, learner-focused programs.
#Education #CertifiedTeacher #IPTE #HAMK#Metropolia #PythonTeaching #Pedagogy #DataAnalytics #TeachingJourney #OpenEducation #JupyterNotebooks #LearningDiary #StudentCentredLearning #DigitalPedagogy #GitHubEducation #FinnishEducation #EdTech
I’ll be honest—doing multidisciplinary research isn’t always smooth sailing. It’s exciting, yes, but it also comes with its fair share of challenges. During my time in the Mobile Futures project, I found myself constantly juggling different perspectives, methodologies, and even ways of thinking. Bringing together data science, sociology, psychology, and economics into one cohesive study felt like solving multiple puzzles at once—each with its own rules and missing pieces.
But that’s the beauty of it, right? The challenge is also the reward.
One of the key tools that made this research possible was Python—and I can’t imagine doing this kind of work without it. Here’s why. 👇
Multidisciplinary research means working with different types of data—from structured survey datasets to unstructured behavioral data. The beauty of Python is that it lets me seamlessly integrate diverse methodologies, whether I’m running statistical models, performing data cleaning, or visualizing behavioral trends.
💡 Why Python?
✔ Flexibility: Python works across disciplines—great for both statistical analysis and machine learning.
✔ Efficiency: Automating repetitive tasks (like data wrangling) saves hours of manual work.
✔ Powerful Libraries: Pandas, NumPy, and Scikit-learn make handling complex data much easier.
Instead of struggling with manual data processing, I was able to focus on making sense of the findings—which is what research should really be about.
If you’ve ever spent hours debugging code, you’ll understand why writing clean, efficient Python scripts is crucial. Early in my research, I realized that messy code = messy analysis.
📷 Below is a snapshot from my Jupyter Notebook, showing the essential Python libraries I used for data processing and visualization.

I relied heavily on Pandas for data manipulation, Matplotlib & Seaborn for visualization, and Scikit-learn for statistical modeling. But even with these great tools, I ran into issues—data inconsistencies, missing values, and errors that took hours to debug.
🚀 What helped?
✔ Writing reusable functions instead of copy-pasting code.
✔ Version-controlling my scripts with Git to track changes.
✔ Using Jupyter Notebooks to document my workflow and visualize results interactively.
These small tweaks saved me so much time in the long run and made my workflow more efficient.
One of the biggest challenges I faced was handling missing and inconsistent survey responses in the European Social Survey (ESS) dataset. If not properly addressed, missing values like "Refusal" or "Don't know" could introduce bias and distort the results.
📷 Here’s an example from the ESS dataset builder, showing how survey responses include missing values that need careful handling.

🧐 How Python helped:
✔ Pandas allowed me to quickly filter, clean, and structure survey data.
✔ Missingno (a Python library) helped visualize missing patterns.
✔ Multiple Imputation in Scikit-learn provided a robust way to estimate missing values.
Without Python, this would have been an exhausting manual process. Instead, I could automate data cleaning, ensuring that my analysis was accurate and reliable.
One of my research questions focused on how different demographic groups engage with the internet. But behavioral data is messy—patterns are influenced by external factors like cultural norms, technological adoption, and accessibility gaps.
📷 Here’s a visualization of the frequency distribution of internet use from different ESS rounds. These graphs illustrate how internet habits shift over time.

📱 How Python made analysis easier:
✔ Seaborn & Matplotlib helped me visualize usage trends over time.
✔ Groupby functions in Pandas allowed me to break data down by demographics.
✔ Scikit-learn helped identify correlations between internet use and attitudes toward migration.
The biggest takeaway? Numbers alone don’t tell the whole story. Python gave me the tools to explore not just the what, but the why behind behavioral shifts.
Working with survey data means dealing with ambiguous and missing responses. Ignoring them wasn’t an option, but incorrectly handling them could skew my results.
📌 Python’s role in fixing this:
✔ Pandas & NumPy helped detect and clean missing data efficiently.
✔ Scikit-learn’s imputation techniques ensured my dataset remained robust.
✔ Sensitivity analysis scripts let me test how different approaches impacted findings.
The result? A dataset I could trust—one that didn’t just fill gaps but preserved the integrity of the analysis.
Multidisciplinary research isn’t easy, but Python made it manageable. It allowed me to:
✅ Automate tedious tasks (instead of getting lost in spreadsheets).
✅ Analyze large datasets quickly (without endless manual cleaning).
✅ Visualize trends in ways that made insights clear and compelling.
Looking back, I can’t imagine tackling this research without Python’s flexibility, efficiency, and powerful libraries. The biggest lesson? The right tools don’t just make research easier—they make better research possible.
💡 What about you? Have you used Python for research? What challenges did you face? Drop a comment—I’d love to hear your experiences! 👇

As part of my practical teacher training at Häme University of Applied Sciences, I designed and delivered an 8-week course titled Data Analytics & Statistics in Python (3 ECTS) at Metropolia UAS in Spring 2025. The course was tailored for Master’s students in Information Technology, focusing on real-world data analysis using Python, Pandas, NumPy, Seaborn, and Matplotlib.
The course structure combined short theoretical lectures with hands-on coding in Jupyter Notebooks, Kahoot quizzes, peer collaboration via Slack, and a final mini-project. Topics ranged from descriptive statistics and probability to time-series and predictive analytics, including a special focus on cryptocurrency market analysis.
I taught 31 students and supervised 19 mini-projects, each aligned with the learners' academic or professional interests (e.g., healthcare, finance, sustainability, media trends). Students uploaded their projects to GitHub and presented them live, showcasing their end-to-end data workflows.
Key Highlights:
– Live online sessions via Zoom (Wednesdays 16:00–18:00 EET)
– Weekly hands-on assignments (30%)
– Capstone mini-project (70%)
– Open resources: GitHub, cheat sheets, videos, discussion forums
| Academic Year | Course | Module Taught | Responsibilities | Hours | Resources |
|---|---|---|---|---|---|
| Spring 2025 | Data Analytics & Statistics in Python | Python for Data Analysis and Visualization | Designing and teaching 8-week course, creating materials, mentoring 19 mini-projects, preparing Jupyter notebooks, quizzes, and grading deliverables | 16 hours teaching + 40 hours course design + 20 hours supervision + 32.5 hours coding |
GitHub Repo DOI: 10.5281/zenodo.15254796 Wakatime: 32 hrs 30 mins |

 As a doctoral candidate who recently graduated from Åbo Akademi University's Faculty of Social Sciences, Business and Economics, and Law, I have had the honour of becoming involved in teaching, especially in the field of information studies. I have had the privilege of creating and presenting some modules for the International Master's program in Governance of Digitalisation, namely "Information Behaviour I" and "Information Behaviour II".
As a doctoral candidate who recently graduated from Åbo Akademi University's Faculty of Social Sciences, Business and Economics, and Law, I have had the honour of becoming involved in teaching, especially in the field of information studies. I have had the privilege of creating and presenting some modules for the International Master's program in Governance of Digitalisation, namely "Information Behaviour I" and "Information Behaviour II".
I tought the "Application of Literacies" module for the "Information Behaviour I" course during the autumn term of 2022. I designed my section to equip students with the necessary skills to navigate our increasingly digital world by thoroughly examining information and digital literacy. Subsequently, during the spring terms of 2022, 2023, and 2024, I had the opportunity to lead a section of 'Information Behaviour II', concentrating on practical application within health information behaviour. These modules were deeply informed by my ongoing doctoral research and spotlighted significant subjects like health information seeking behaviour and the health belief model. These responsibilities are detailed in Table 2.
| Academic Year | Course | Module Taught | Responsibilities | Hours |
|---|---|---|---|---|
| Spring 2024 | Information Behaviour II | Health Information Behaviour (Focus on Health Information Seeking Behaviour and the Health Belief Model) | Preparing and recording lectures, engaging students in group assignments, and learning diaries, grading activities | 1 hour’s teaching + 15 hours supervision |
| Spring 2023 | Information Behaviour II | Health Information Behaviour (Focus on Health Information Seeking Behaviour and the Health Belief Model) | Preparing and recording lectures, engaging students in group assignments, and learning diaries, grading activities | 1 hour’s teaching + 15 hours supervision |
| Autumn 2022 | Information Behaviour I | Application of Literacies (Focus on Information and Digital Literacy) | Preparing and recording lectures, engaging students in group assignments, and learning diaries, grading activities | 1 hour’s teaching + 15 hours supervision |
| Spring 2022 | Information Behaviour II | Health Information Behaviour (Focus on Health Information Seeking Behaviour and the Health Belief Model) | Preparing and recording lectures, engaging students in group assignments, and learning diaries, grading activities | 1 hour’s teaching + 15 hours supervision |
 From 2011 to 2014, I worked as a lecturer and researcher at Islamic Azad University before moving to Finland to pursue my second master's degree and subsequent doctorate. This position provided me with invaluable experience in effectively teaching undergraduates intricate concepts in business administration, taxation, finance, and accounting.
My pedagogical approach was based on helping students improve their scientific knowledge and research skills through creative and engaging teaching methods, while also acknowledging their accomplishments. These experiences, combined with my ongoing commitment to professional development, have given me greater confidence in my ability to contribute meaningfully to scientific research and academic lecturing. Table 2 provides more information on the courses I taught at Azad University from 2011 to 2014, including semester/year, course code, level, type, credits, and teaching hours per semester. These responsibilities are detailed in Table 3.
From 2011 to 2014, I worked as a lecturer and researcher at Islamic Azad University before moving to Finland to pursue my second master's degree and subsequent doctorate. This position provided me with invaluable experience in effectively teaching undergraduates intricate concepts in business administration, taxation, finance, and accounting.
My pedagogical approach was based on helping students improve their scientific knowledge and research skills through creative and engaging teaching methods, while also acknowledging their accomplishments. These experiences, combined with my ongoing commitment to professional development, have given me greater confidence in my ability to contribute meaningfully to scientific research and academic lecturing. Table 2 provides more information on the courses I taught at Azad University from 2011 to 2014, including semester/year, course code, level, type, credits, and teaching hours per semester. These responsibilities are detailed in Table 3.
| Course | Semester/Year | Code | Level | Type | Credits | HPS[1] |
|---|---|---|---|---|---|---|
| Investing in Stock Exchange | Summer 2012-2013 | 718 | Bachelor | Core | 2 | 32 |
| Finance 2 | Summer 2012-2013 | 1309 | Bachelor | Core | 3 | 48 |
| Tax Accounting | 2nd 2012-2013 | 4092 | Associate | Core - Elective | 2 | 32 |
| Tax Accounting | 2nd 2012-2013 | 4091 | Associate | Core - Elective | 2 | 32 |
| Finance Class | 2nd 2010-2011 | 7356 | Bachelor | Core | 3 | 48 |
| Tax Accounting | 1st 2013-2014 | 1603 | Associate | Core - Elective | 2 | 32 |
| Finance 1 | 1st 2011-2012 | 4883 | Bachelor | Core | 3 | 48 |
| Computer Application in Accounting - 2 | 1st 2011-2012 | 11511 | Bachelor | Core - Elective | 2 | 32 |
For more information about teaching hours and course credits at Islamic Azad University, refer to:
 “Education is not to be viewed as something like filling a vessel with water but, rather, assisting a flower to grow in its own way”
“Education is not to be viewed as something like filling a vessel with water but, rather, assisting a flower to grow in its own way”My teaching philosophy prioritizes creating a safe and engaging learning environment where students feel comfortable expressing their ideas and are encouraged to learn and grow. To achieve this, I use a variety of teaching techniques, including the use of technology and storytelling, to help students better understand complex concepts.
I believe in using concrete examples to explain abstract financial concepts, as this approach helps students connect theoretical concepts to real-life situations and provides them with practical knowledge. For instance, when teaching about present and future value, I relate it to a concrete example of a person saving for a vehicle purchase, which helps students better grasp the concept.
 1- The Principles of Digital Pedagogy in Instruction and Teaching (2 ECTS) - (complited) - University of Eastern Finland
1- The Principles of Digital Pedagogy in Instruction and Teaching (2 ECTS) - (complited) - University of Eastern Finland
2- Introduction to Educational Leadership (5ECTS) - (complited) - Tampere University of Applied Sciences (TAMK)
 1- Didactical design of courses in higher education (5ECTS) - (complited) - Åbo Akademi University
1- Didactical design of courses in higher education (5ECTS) - (complited) - Åbo Akademi University
2- Teaching Practice 1 (5 ECTS) - (complited)- Åbo Akademi University
3- Digital learning in higher education (5 ECTS) - (complited)- Åbo Akademi University
4- Digital Didaktik in Higher Education (5 ECTS) - (complited)- Åbo Akademi University
1. The Teacher as an Expert of Learning – 28 ECTS
2. The Teacher as a Pedagogical Actor – 15 ECTS
3. Optional Studies – 5 ECTS






 Management accounting has evolved significantly over the past decades, integrating modern theories and innovative approaches to enhance decision-making processes within organizations. This book provides a comprehensive analysis of contemporary management accounting practices, aligning them with emerging theoretical frameworks. Written in Farsi and developed within the Iranian academic and business context, the book critically examines traditional cost management techniques while exploring strategic cost management, performance measurement systems, and behavioral aspects of accounting. Drawing from both global and local perspectives, the book discusses the impact of modern economic theories, information technology advancements, and data-driven decision-making on management accounting. Additionally, it highlights the role of sustainability, digital transformation, and corporate governance in shaping accounting practices. By incorporating empirical evidence and case studies relevant to Iran’s economic landscape, this work serves as a valuable resource for academics, professionals, and students seeking to understand the evolving role of management accounting in today’s dynamic business environment. This book aims to bridge the gap between theory and practice, fostering a deeper understanding of how modern management accounting principles can enhance strategic planning, risk management, and organizational performance in an era of rapid economic and technological changes.
Management accounting has evolved significantly over the past decades, integrating modern theories and innovative approaches to enhance decision-making processes within organizations. This book provides a comprehensive analysis of contemporary management accounting practices, aligning them with emerging theoretical frameworks. Written in Farsi and developed within the Iranian academic and business context, the book critically examines traditional cost management techniques while exploring strategic cost management, performance measurement systems, and behavioral aspects of accounting. Drawing from both global and local perspectives, the book discusses the impact of modern economic theories, information technology advancements, and data-driven decision-making on management accounting. Additionally, it highlights the role of sustainability, digital transformation, and corporate governance in shaping accounting practices. By incorporating empirical evidence and case studies relevant to Iran’s economic landscape, this work serves as a valuable resource for academics, professionals, and students seeking to understand the evolving role of management accounting in today’s dynamic business environment. This book aims to bridge the gap between theory and practice, fostering a deeper understanding of how modern management accounting principles can enhance strategic planning, risk management, and organizational performance in an era of rapid economic and technological changes. This book provides a comprehensive analysis of tax accounting principles with a particular focus on Value Added Tax (VAT) within the Iranian context. Written in Farsi, the book explores the theoretical foundations and practical applications of tax accounting, offering insights into Iran’s tax regulations, VAT implementation, and its impact on businesses and financial reporting. It discusses the legal framework, compliance requirements, and challenges associated with VAT administration while comparing Iran’s tax system with international standards. The book serves as a valuable resource for tax professionals, accountants, researchers, and policymakers seeking to understand the complexities of tax accounting and VAT in Iran.
This book provides a comprehensive analysis of tax accounting principles with a particular focus on Value Added Tax (VAT) within the Iranian context. Written in Farsi, the book explores the theoretical foundations and practical applications of tax accounting, offering insights into Iran’s tax regulations, VAT implementation, and its impact on businesses and financial reporting. It discusses the legal framework, compliance requirements, and challenges associated with VAT administration while comparing Iran’s tax system with international standards. The book serves as a valuable resource for tax professionals, accountants, researchers, and policymakers seeking to understand the complexities of tax accounting and VAT in Iran. Mutual funds play a crucial role in financial markets by providing investors with diversified investment opportunities and professional management. This book offers an in-depth analysis of the mutual fund industry in Iran, examining its structure, regulatory framework, and performance assessment methods. The book explores key aspects of mutual fund management, including fund selection, portfolio diversification, risk management, and investment strategies. It also evaluates various performance measurement models, such as risk-adjusted return metrics, benchmarking techniques, and the impact of economic and market conditions on fund performance. A comparative analysis with international practices is provided to highlight Iran’s unique challenges and opportunities in the mutual fund sector. Moreover, the book addresses the role of fund managers, investor behavior, and regulatory policies in shaping the mutual fund landscape. By integrating theoretical foundations with empirical data, this study offers valuable insights for academics, financial professionals, policymakers, and investors interested in the Iranian mutual fund market. This book serves as a comprehensive guide for understanding mutual fund operations and performance evaluation in Iran, contributing to the broader discourse on investment management in emerging economies.
Mutual funds play a crucial role in financial markets by providing investors with diversified investment opportunities and professional management. This book offers an in-depth analysis of the mutual fund industry in Iran, examining its structure, regulatory framework, and performance assessment methods. The book explores key aspects of mutual fund management, including fund selection, portfolio diversification, risk management, and investment strategies. It also evaluates various performance measurement models, such as risk-adjusted return metrics, benchmarking techniques, and the impact of economic and market conditions on fund performance. A comparative analysis with international practices is provided to highlight Iran’s unique challenges and opportunities in the mutual fund sector. Moreover, the book addresses the role of fund managers, investor behavior, and regulatory policies in shaping the mutual fund landscape. By integrating theoretical foundations with empirical data, this study offers valuable insights for academics, financial professionals, policymakers, and investors interested in the Iranian mutual fund market. This book serves as a comprehensive guide for understanding mutual fund operations and performance evaluation in Iran, contributing to the broader discourse on investment management in emerging economies. The financial sector plays a crucial role in economic stability, and effective risk management is essential for maintaining the resilience of banks, financial institutions, and credit organizations. This book provides a comprehensive analysis of risk management frameworks, methodologies, and regulatory requirements, with a particular focus on quantitative modeling approaches. Written in the context of the Iranian banking and financial system, the book integrates theoretical insights with practical applications, addressing key risks such as credit, market, liquidity, and operational risks.
The financial sector plays a crucial role in economic stability, and effective risk management is essential for maintaining the resilience of banks, financial institutions, and credit organizations. This book provides a comprehensive analysis of risk management frameworks, methodologies, and regulatory requirements, with a particular focus on quantitative modeling approaches. Written in the context of the Iranian banking and financial system, the book integrates theoretical insights with practical applications, addressing key risks such as credit, market, liquidity, and operational risks./filters:quality(100)/prod01/channel_3/media/tcd/sociology/images/ECSR-2026.png)
 The integration of skilled immigrants into European labor markets is a pressing issue, particularly as demographic changes and labor shortages challenge national economies. This study critically reviews key integration programs across Europe assessing their effectiveness in addressing skill gaps and fostering economic inclusion. By adopting a comparative policy analysis approach, this review examines residency and work permit structures, sector-specific support mechanisms, and cultural adaptation strategies. The findings highlight common challenges such as underemployment, foreign credential recognition, and cultural adaptation barriers while underscoring successful strategies, including language training, vocational upskilling, and employer incentives for hiring skilled migrants. This research contributes to the ongoing discourse on two-way integration—ensuring both immigrants and host societies benefit from structured policy interventions. By identifying best practices and policy gaps, the study advocates for streamlined qualification recognition, proactive community engagement, and long-term policy flexibility to enhance labor market participation for skilled migrants. These insights serve as a foundation for evidence-based policymaking and future research on socioeconomic integration frameworks in the European context.
The integration of skilled immigrants into European labor markets is a pressing issue, particularly as demographic changes and labor shortages challenge national economies. This study critically reviews key integration programs across Europe assessing their effectiveness in addressing skill gaps and fostering economic inclusion. By adopting a comparative policy analysis approach, this review examines residency and work permit structures, sector-specific support mechanisms, and cultural adaptation strategies. The findings highlight common challenges such as underemployment, foreign credential recognition, and cultural adaptation barriers while underscoring successful strategies, including language training, vocational upskilling, and employer incentives for hiring skilled migrants. This research contributes to the ongoing discourse on two-way integration—ensuring both immigrants and host societies benefit from structured policy interventions. By identifying best practices and policy gaps, the study advocates for streamlined qualification recognition, proactive community engagement, and long-term policy flexibility to enhance labor market participation for skilled migrants. These insights serve as a foundation for evidence-based policymaking and future research on socioeconomic integration frameworks in the European context. As Europe faces evolving migration patterns, the integration of skilled immigrants remains a crucial socio-economic challenge. This study explores innovative community-based approaches that enhance skilled immigrants’ access to local labor markets, professional networks, and social services. Through a comparative analysis of successful European models. This research highlights effective policies that align with labor market demands and foster long-term socio-economic inclusion. By examining barriers such as underemployment, recognition of foreign qualifications, and cultural adaptation, this study identifies best practices for facilitating smoother transitions into host economies. Key recommendations include enhancing language and vocational training, streamlining credential recognition, promoting inclusive hiring policies, and fostering mentorship programs that connect skilled immigrants with local professionals. The findings advocate for community-driven integration models that prioritize policy flexibility, employer incentives, and sustained governmental support. Addressing these integration challenges not only mitigates skill shortages but also strengthens economic resilience and social cohesion across European societies. This research underscores the importance of a holistic, adaptive, and collaborative approach to integration, ensuring that skilled immigrants contribute meaningfully to their new communities.
As Europe faces evolving migration patterns, the integration of skilled immigrants remains a crucial socio-economic challenge. This study explores innovative community-based approaches that enhance skilled immigrants’ access to local labor markets, professional networks, and social services. Through a comparative analysis of successful European models. This research highlights effective policies that align with labor market demands and foster long-term socio-economic inclusion. By examining barriers such as underemployment, recognition of foreign qualifications, and cultural adaptation, this study identifies best practices for facilitating smoother transitions into host economies. Key recommendations include enhancing language and vocational training, streamlining credential recognition, promoting inclusive hiring policies, and fostering mentorship programs that connect skilled immigrants with local professionals. The findings advocate for community-driven integration models that prioritize policy flexibility, employer incentives, and sustained governmental support. Addressing these integration challenges not only mitigates skill shortages but also strengthens economic resilience and social cohesion across European societies. This research underscores the importance of a holistic, adaptive, and collaborative approach to integration, ensuring that skilled immigrants contribute meaningfully to their new communities. Background— Studies on people with asylum-seeking backgrounds reveal different needs for and challenges with utilisation of health-related information and healthcare services in host countries. In order to explore such needs and challenges, we need to identify influential factors that affect the motivation of people with asylum-seeking background to seek health-related information and healthcare services. Awareness of a health problem and cues to action may vary from one person to another. Cues to action may, moreover, it can be internal (such as symptoms or changes in body shape) or external (such as messages). Studying cues to action, particularly among minorities with different ethnic backgrounds is therefore important. Purpose: This study investigates internal and external cues to take health actions among people with asylum-seeking background living in the two Nordic countries Finland and Norway. Design/methodology/approach: Two sets of semi-structured interviews were conducted from May to August 2022 with a total of 16 participants with asylum-seeking background in Finland (N = 7) and Norway (N = 9). The interview guide was developed based on the Health Belief Model (HBM) to identify internal and external factors acting as motivators for taking health actions in the studied group. Results- The findings indicate that common cues to health actions among the participants were related to changes in health, access to free medical check-ups, health educational TV or radio programmes, and social media. The participants mentioned different internal and external motivations for taking health action, which correspond to their cultural differences or beliefs. These were advice from family members and friends, advice from a healthcare professional from their country of origin and receiving information about physical or mental health risk factors at church, mosque, or their community meeting. Finally, receiving information about physical or mental health risk factors from universities, employers, local health authorities, or medical professionals, and advice from a local healthcare professional were reported more among participants from the Norwegian sample group (three out of nine) compared with the Finnish sample group (one out of seven). Findings-The findings reveal that while different officials and stakeholders provide health-related information in terms of emails, letters (such as invitation letters for mammography check-ups), and guidelines to non-native minorities; only a small part of this information will reach and be used by the target population. Practical implications: This study has twofold practical implications, (a) to provide practical insights to healthcare providers, immigration authorities, and policymakers on factors influencing taking health action among non-native minorities, and (b) to highlight the role of cultural factors and beliefs in the utilisation of different health-related information and healthcare services among minorities in Nordic countries. The findings showed factors such as health-information being simple, related to the immediate health needs of the audience, as well as easy to access are the most important factors that lead to more utilisation of health-related information and healthcare services among the studied population. Originality/value: This is one of the first studies on cues to health actions among residents with asylum-seeking background living in two Nordic countries and provides reflections on the role of personal social networks and official cues in providing awareness of health problems.
Background— Studies on people with asylum-seeking backgrounds reveal different needs for and challenges with utilisation of health-related information and healthcare services in host countries. In order to explore such needs and challenges, we need to identify influential factors that affect the motivation of people with asylum-seeking background to seek health-related information and healthcare services. Awareness of a health problem and cues to action may vary from one person to another. Cues to action may, moreover, it can be internal (such as symptoms or changes in body shape) or external (such as messages). Studying cues to action, particularly among minorities with different ethnic backgrounds is therefore important. Purpose: This study investigates internal and external cues to take health actions among people with asylum-seeking background living in the two Nordic countries Finland and Norway. Design/methodology/approach: Two sets of semi-structured interviews were conducted from May to August 2022 with a total of 16 participants with asylum-seeking background in Finland (N = 7) and Norway (N = 9). The interview guide was developed based on the Health Belief Model (HBM) to identify internal and external factors acting as motivators for taking health actions in the studied group. Results- The findings indicate that common cues to health actions among the participants were related to changes in health, access to free medical check-ups, health educational TV or radio programmes, and social media. The participants mentioned different internal and external motivations for taking health action, which correspond to their cultural differences or beliefs. These were advice from family members and friends, advice from a healthcare professional from their country of origin and receiving information about physical or mental health risk factors at church, mosque, or their community meeting. Finally, receiving information about physical or mental health risk factors from universities, employers, local health authorities, or medical professionals, and advice from a local healthcare professional were reported more among participants from the Norwegian sample group (three out of nine) compared with the Finnish sample group (one out of seven). Findings-The findings reveal that while different officials and stakeholders provide health-related information in terms of emails, letters (such as invitation letters for mammography check-ups), and guidelines to non-native minorities; only a small part of this information will reach and be used by the target population. Practical implications: This study has twofold practical implications, (a) to provide practical insights to healthcare providers, immigration authorities, and policymakers on factors influencing taking health action among non-native minorities, and (b) to highlight the role of cultural factors and beliefs in the utilisation of different health-related information and healthcare services among minorities in Nordic countries. The findings showed factors such as health-information being simple, related to the immediate health needs of the audience, as well as easy to access are the most important factors that lead to more utilisation of health-related information and healthcare services among the studied population. Originality/value: This is one of the first studies on cues to health actions among residents with asylum-seeking background living in two Nordic countries and provides reflections on the role of personal social networks and official cues in providing awareness of health problems. Over the course of the last few decades, the Nordic countries are facing a change in their population structure, with a growing number of immigrants including people with asylum-seeking and refugee backgrounds. Almost three million people have moved to the Nordic countries in the last decade (Nordic Welfare Centre, 2017). For example, in Norway the number of asylum seekers for 2015 was 31,150 and the number of refugees for 2021 was 46,042 (Macro-trends, 2022; Statista, 2022). However, it should be noted that these individ-uals (asylum seekers and refugees) have diverse cultural and ethnical back-grounds, which means they may have different approaches toward seeking health information or healthcare services in their host country (Ahmadinia et al., 2021). Providing adequate and timely health information services for these people is one of the main challenges of the Nordic healthcare system (Haj-Younes et al., 2022). Therefore, a primary step to overcome this challenge is to understand what health-related information and healthcare services these individuals might need. This study aims to address this research gap by inves-tigating their information seeking behaviour from the perspective of cultural and ethnical background. Health information-seeking behaviour and health-care-seeking behaviour are two main key terms in this study. Health informa-tion-seeking behaviour refers to any situation in which an individual needs or uses any health-related information, while healthcare seeking behaviour refers to any activity undertaken by an individual who perceived himself to have a health concern, or to be sick, for the purpose of finding an appropriate reme-dy (Lalazaryan and Zare-Farashbandi, 2014; Ward et al., 1997). This extend-ed abstract, is a part of larger study including interviews also in Finland and Sweden, and presents preliminary findings of an original qualitative study on people with asylum seeking background and their health seeking behaviour in terms of health-related needs and utilisation in Norway
Over the course of the last few decades, the Nordic countries are facing a change in their population structure, with a growing number of immigrants including people with asylum-seeking and refugee backgrounds. Almost three million people have moved to the Nordic countries in the last decade (Nordic Welfare Centre, 2017). For example, in Norway the number of asylum seekers for 2015 was 31,150 and the number of refugees for 2021 was 46,042 (Macro-trends, 2022; Statista, 2022). However, it should be noted that these individ-uals (asylum seekers and refugees) have diverse cultural and ethnical back-grounds, which means they may have different approaches toward seeking health information or healthcare services in their host country (Ahmadinia et al., 2021). Providing adequate and timely health information services for these people is one of the main challenges of the Nordic healthcare system (Haj-Younes et al., 2022). Therefore, a primary step to overcome this challenge is to understand what health-related information and healthcare services these individuals might need. This study aims to address this research gap by inves-tigating their information seeking behaviour from the perspective of cultural and ethnical background. Health information-seeking behaviour and health-care-seeking behaviour are two main key terms in this study. Health informa-tion-seeking behaviour refers to any situation in which an individual needs or uses any health-related information, while healthcare seeking behaviour refers to any activity undertaken by an individual who perceived himself to have a health concern, or to be sick, for the purpose of finding an appropriate reme-dy (Lalazaryan and Zare-Farashbandi, 2014; Ward et al., 1997). This extend-ed abstract, is a part of larger study including interviews also in Finland and Sweden, and presents preliminary findings of an original qualitative study on people with asylum seeking background and their health seeking behaviour in terms of health-related needs and utilisation in Norway This article reviews health beliefs, and attitudes of asylum seekers and refugees, using an adapted framework of the Health Belief Model. The systematic review included 15 peer-reviewed records retrieved from CINAHL, Medline, PubMed, PsycINFO, and PsycArticles. Findings of this review show culture, tradition, fate or destiny, psychological factors, family, friends, and community were crucial influential factors in shaping asylum seekers, and refugees’ perceived barriers, fear, severity, and susceptibility in their health-seeking activities. In addition, knowledge and awareness related to the benefits of using modern healthcare services were motivators for different ethnic groups to take care of their personal health. Healthcare providers, educational programs, and support from family, friends, and community had noteworthy influence on triggering the health-related decision-making process among asylum seekers and refugees. This study offers practical implications for healthcare providers and public health community to devise culturally relevant strategies that will effectively target asylum seekers and refugees with diverse cultural, traditional and attitudinal beliefs about healthcare and health seeking activities. This is one of the descriptive review studies on asylum seekers and refugees’ health beliefs and their health-seeking behavior based on ethnicity grounds.
This article reviews health beliefs, and attitudes of asylum seekers and refugees, using an adapted framework of the Health Belief Model. The systematic review included 15 peer-reviewed records retrieved from CINAHL, Medline, PubMed, PsycINFO, and PsycArticles. Findings of this review show culture, tradition, fate or destiny, psychological factors, family, friends, and community were crucial influential factors in shaping asylum seekers, and refugees’ perceived barriers, fear, severity, and susceptibility in their health-seeking activities. In addition, knowledge and awareness related to the benefits of using modern healthcare services were motivators for different ethnic groups to take care of their personal health. Healthcare providers, educational programs, and support from family, friends, and community had noteworthy influence on triggering the health-related decision-making process among asylum seekers and refugees. This study offers practical implications for healthcare providers and public health community to devise culturally relevant strategies that will effectively target asylum seekers and refugees with diverse cultural, traditional and attitudinal beliefs about healthcare and health seeking activities. This is one of the descriptive review studies on asylum seekers and refugees’ health beliefs and their health-seeking behavior based on ethnicity grounds. During the ongoing outbreak of coronavirus people acquire and exchange health information about COVID-19 through different communication chan-nels. It is important to understand the role of individuals as information sources, and gain understanding on health information seeking behavior among language minorities during a pandemic.Lalazaryan & Zare-Farashbandi (2014) described health information seeking behavior as any individual’s activities that are related to seeking, obtaining, and making use of health information either regarding illnesses or treatments. In a pandemic, the health information seeking focus may change more towards securing one’s own health and supporting the close ones in the same crisis (Dreisiebner, März, Mandl, 2020). World Health Organisation (WHO) declared COVID-19 as a public health emergency of international concern (Jee, 2020; WHO, 2020). A pandemic raises feelings like fear, worry and anxiety. Mental health concerns have been raised in tow of the pandemic because of numerous reasons. One of them is the isolation millions of people have endured during the first and the ongoing second wave of COVID-19. WHO has established mental health recommen-dations of how individuals can care for their mental health during times of crisis. In these recommendations family and friends play a role, for instance in following ways: “keep in touch with friends and family”, “establish a support network”, “develop a feeling of belonging to the collective care process” (WHO, 2018).
During the ongoing outbreak of coronavirus people acquire and exchange health information about COVID-19 through different communication chan-nels. It is important to understand the role of individuals as information sources, and gain understanding on health information seeking behavior among language minorities during a pandemic.Lalazaryan & Zare-Farashbandi (2014) described health information seeking behavior as any individual’s activities that are related to seeking, obtaining, and making use of health information either regarding illnesses or treatments. In a pandemic, the health information seeking focus may change more towards securing one’s own health and supporting the close ones in the same crisis (Dreisiebner, März, Mandl, 2020). World Health Organisation (WHO) declared COVID-19 as a public health emergency of international concern (Jee, 2020; WHO, 2020). A pandemic raises feelings like fear, worry and anxiety. Mental health concerns have been raised in tow of the pandemic because of numerous reasons. One of them is the isolation millions of people have endured during the first and the ongoing second wave of COVID-19. WHO has established mental health recommen-dations of how individuals can care for their mental health during times of crisis. In these recommendations family and friends play a role, for instance in following ways: “keep in touch with friends and family”, “establish a support network”, “develop a feeling of belonging to the collective care process” (WHO, 2018). Background— Studies on people with asylum-seeking backgrounds reveal different needs for and challenges with utilisation of health-related information and healthcare services in host countries. In order to explore such needs and challenges, we need to identify influential factors that affect the motivation of people with asylum-seeking background to seek health-related information and healthcare services. Awareness of a health problem and cues to action may vary from one person to another. Cues to action may, moreover, it can be internal (such as symptoms or changes in body shape) or external (such as messages). Studying cues to action, particularly among minorities with different ethnic backgrounds is therefore important. Purpose: This study investigates internal and external cues to take health actions among people with asylum-seeking background living in the two Nordic countries Finland and Norway.
Background— Studies on people with asylum-seeking backgrounds reveal different needs for and challenges with utilisation of health-related information and healthcare services in host countries. In order to explore such needs and challenges, we need to identify influential factors that affect the motivation of people with asylum-seeking background to seek health-related information and healthcare services. Awareness of a health problem and cues to action may vary from one person to another. Cues to action may, moreover, it can be internal (such as symptoms or changes in body shape) or external (such as messages). Studying cues to action, particularly among minorities with different ethnic backgrounds is therefore important. Purpose: This study investigates internal and external cues to take health actions among people with asylum-seeking background living in the two Nordic countries Finland and Norway. This article explores the role of virtual organizations in managing customer relationships, with a focus on the effects of these organizations on various domains, such as resource planning, customer relationship management, and web services. It discusses the importance of integrating organizational processes and technologies to improve communication with customers and create long-term relationships. The impact of virtual organizations on customer behavior and value creation is emphasized, particularly in relation to the development and implementation of customer relationship management strategies.
This article explores the role of virtual organizations in managing customer relationships, with a focus on the effects of these organizations on various domains, such as resource planning, customer relationship management, and web services. It discusses the importance of integrating organizational processes and technologies to improve communication with customers and create long-term relationships. The impact of virtual organizations on customer behavior and value creation is emphasized, particularly in relation to the development and implementation of customer relationship management strategies. This article aims to explore how managers can ensure their businesses are not exposed to undue risk levels and determine whether organizational management aligns with expectations. By utilizing control levers, management and organizations can identify existing challenges and employ diagnostic, boundary, belief (value-based), and interactive control systems to achieve organizational objectives. Each of these components plays a critical role in identifying limitations and proposing solutions for management. This article provides an overview of control levers at the organizational level.
This article aims to explore how managers can ensure their businesses are not exposed to undue risk levels and determine whether organizational management aligns with expectations. By utilizing control levers, management and organizations can identify existing challenges and employ diagnostic, boundary, belief (value-based), and interactive control systems to achieve organizational objectives. Each of these components plays a critical role in identifying limitations and proposing solutions for management. This article provides an overview of control levers at the organizational level. Since the emergence of distributed networks, numerous practical opportunities have arisen for identifying and recording events in real-time. Efforts have also been dedicated to addressing information challenges such as data currency and authenticity. However, there remain issues and shortcomings in achieving optimal maintenance of monetary, financial, and accounting records. To address this, careful attention must be paid to the distribution of information systems within network environments. It is essential to maintain a continuous flow of updated information and eliminate restrictions on the formulation of assumptions and foundational frameworks for their use by administrators, management teams, or sites. The Grid (a system for information sharing), as proposed by Ian Foster and Carl Kesselman, establishes secure communication channels to enable shared processing of resources and data across virtual organizations.
Since the emergence of distributed networks, numerous practical opportunities have arisen for identifying and recording events in real-time. Efforts have also been dedicated to addressing information challenges such as data currency and authenticity. However, there remain issues and shortcomings in achieving optimal maintenance of monetary, financial, and accounting records. To address this, careful attention must be paid to the distribution of information systems within network environments. It is essential to maintain a continuous flow of updated information and eliminate restrictions on the formulation of assumptions and foundational frameworks for their use by administrators, management teams, or sites. The Grid (a system for information sharing), as proposed by Ian Foster and Carl Kesselman, establishes secure communication channels to enable shared processing of resources and data across virtual organizations. The purpose of this study is to assess the efficiency and performance of portfolio management in investment companies listed on the TSE, which were holding active portfolios during the years 2005 to 2009. The study employed Modern Portfolio Theory (MPT) and Postmodern Portfolio Theory (PMPT) to evaluate performance, utilising the Sharpe, Sortino, and Sterling ratios. The first hypothesis was not accepted based on one-way ANOVA and pairwise mean comparison using LSD post hoc tests, which showed that the Sterling ratio was the highest for all three metrics but not significantly different, as it was nearly the best. The second hypothesis tested the performance of the companies in relation to the market, and all metrics signalled that the series was superior to the market except the Sortino ratio. Lastly, the Kruskal-Wallis test and Chi-square statistic showed identical rankings between all three measures.
The purpose of this study is to assess the efficiency and performance of portfolio management in investment companies listed on the TSE, which were holding active portfolios during the years 2005 to 2009. The study employed Modern Portfolio Theory (MPT) and Postmodern Portfolio Theory (PMPT) to evaluate performance, utilising the Sharpe, Sortino, and Sterling ratios. The first hypothesis was not accepted based on one-way ANOVA and pairwise mean comparison using LSD post hoc tests, which showed that the Sterling ratio was the highest for all three metrics but not significantly different, as it was nearly the best. The second hypothesis tested the performance of the companies in relation to the market, and all metrics signalled that the series was superior to the market except the Sortino ratio. Lastly, the Kruskal-Wallis test and Chi-square statistic showed identical rankings between all three measures.
 Recent studies have rigorously analysed the factors that lead to suboptimal judgements made by management. A variety of studies investigate the capacity of organisational management to function independently and thoughtfully in decision-making, ensuring that factors like changes in the operational environment do not adversely affect their choices. This issue is significant for investors due to their separation from managerial decision-making processes, which makes it challenging for them to understand the rationale behind management's choices in recording economic events. Consequently, changes in the environment and shifting decision-making contexts require managers to adjust accordingly. This study examines the processing of information and the factors that influence management perspectives, re-evaluating Selfridge’s theory and its impact on organisational decision-making and information systems. The study highlights the importance of behavioural research in enhancing organisational transparency and aligning stakeholder interests.
Recent studies have rigorously analysed the factors that lead to suboptimal judgements made by management. A variety of studies investigate the capacity of organisational management to function independently and thoughtfully in decision-making, ensuring that factors like changes in the operational environment do not adversely affect their choices. This issue is significant for investors due to their separation from managerial decision-making processes, which makes it challenging for them to understand the rationale behind management's choices in recording economic events. Consequently, changes in the environment and shifting decision-making contexts require managers to adjust accordingly. This study examines the processing of information and the factors that influence management perspectives, re-evaluating Selfridge’s theory and its impact on organisational decision-making and information systems. The study highlights the importance of behavioural research in enhancing organisational transparency and aligning stakeholder interests. One of the key approaches to managerial control and enhancing transparency in organisations is the use of control levers. Governance levers, for instance, establish self-regulation as part of internal organisational governance. This not only reduces agency costs but also addresses conflicts of interest between management, shareholders, and other stakeholders. By aligning organisational structures with the interests of stakeholders and rights-holders, the value-creation process within the organisation is optimised. Control levers can also be seen as tools for the continuous monitoring and evaluation of organisational units and departments, ensuring alignment between operations and predefined plans. Thus, control levers play a vital role in organisational governance and are essential for its effectiveness.
One of the key approaches to managerial control and enhancing transparency in organisations is the use of control levers. Governance levers, for instance, establish self-regulation as part of internal organisational governance. This not only reduces agency costs but also addresses conflicts of interest between management, shareholders, and other stakeholders. By aligning organisational structures with the interests of stakeholders and rights-holders, the value-creation process within the organisation is optimised. Control levers can also be seen as tools for the continuous monitoring and evaluation of organisational units and departments, ensuring alignment between operations and predefined plans. Thus, control levers play a vital role in organisational governance and are essential for its effectiveness. This study examines the portfolio management efficacy of investment firms on the Tehran Stock Exchange (TSE) from 2005 to 2009. The study assesses whether these enterprises surpassed the larger market by employing performance measurements such as the Sharpe, Treynor, and Jensen ratios, in addition to the M² and appraisal ratios. This analysis further examines how economic conditions, as emphasised in the Central Bank’s monthly reports, influenced their portfolios. The findings indicated that certain investment firms outperformed the market in portfolio management. This is significant since it implies that during financial crises—when markets are unstable—investing in these companies may be more prudent than acquiring shares of other organisations or attempting to construct an independent portfolio from the ground up. However, upon further examination of economic factors, one component emerged prominently. Through stepwise regression, a statistical technique for identifying principal determinants, they determined that exchange rate changes exerted the most significant influence on the profits of these enterprises. In other words, fluctuations in currency prices directly influenced the performance of these investment enterprises. This serves as a valuable alert for investors. In times of market upheaval, relying on proficient portfolio managers (such as these firms) may be a more prudent choice than managing independently. Furthermore, monitoring currency trends may assist in forecasting their success.
This study examines the portfolio management efficacy of investment firms on the Tehran Stock Exchange (TSE) from 2005 to 2009. The study assesses whether these enterprises surpassed the larger market by employing performance measurements such as the Sharpe, Treynor, and Jensen ratios, in addition to the M² and appraisal ratios. This analysis further examines how economic conditions, as emphasised in the Central Bank’s monthly reports, influenced their portfolios. The findings indicated that certain investment firms outperformed the market in portfolio management. This is significant since it implies that during financial crises—when markets are unstable—investing in these companies may be more prudent than acquiring shares of other organisations or attempting to construct an independent portfolio from the ground up. However, upon further examination of economic factors, one component emerged prominently. Through stepwise regression, a statistical technique for identifying principal determinants, they determined that exchange rate changes exerted the most significant influence on the profits of these enterprises. In other words, fluctuations in currency prices directly influenced the performance of these investment enterprises. This serves as a valuable alert for investors. In times of market upheaval, relying on proficient portfolio managers (such as these firms) may be a more prudent choice than managing independently. Furthermore, monitoring currency trends may assist in forecasting their success. Subsequent to the adoption of the Capital Asset Pricing Model (CAPM), various modifications have been implemented. The incorporation of variables such as financial risks, liquidity, adverse factors, unforeseen events, and economic and operational elements has augmented the model's efficacy. As a result of these developments, new models have emerged based on the standard CAPM. Examples include the Revised Capital Asset Pricing Model, proposed in 2009 by Iranian researchers Dr. Rahnama-ye Roodpashti and Dr. Amirhosseini. This model demonstrates greater capability in interpreting capital assets by accounting for market conditions, the prevailing state of economic units, and investment portfolios. In this study, given the importance of applying these models for financial managers, economic analysts, and investors, we introduce and critically examine each of these models.
Subsequent to the adoption of the Capital Asset Pricing Model (CAPM), various modifications have been implemented. The incorporation of variables such as financial risks, liquidity, adverse factors, unforeseen events, and economic and operational elements has augmented the model's efficacy. As a result of these developments, new models have emerged based on the standard CAPM. Examples include the Revised Capital Asset Pricing Model, proposed in 2009 by Iranian researchers Dr. Rahnama-ye Roodpashti and Dr. Amirhosseini. This model demonstrates greater capability in interpreting capital assets by accounting for market conditions, the prevailing state of economic units, and investment portfolios. In this study, given the importance of applying these models for financial managers, economic analysts, and investors, we introduce and critically examine each of these models. The impact of long-term financing on the company's return level is among the topics of interest to both creditors and investors. Therefore, this study aims to investigate this issue by examining a sample of companies listed on the Tehran Stock Exchange during the years 2005 to 2011, focusing on the financial leverage effect on the company's return. Of course, in order to achieve suitable results, the two groups of debt have been categorized based on the ratio of debt to total assets. The findings indicate that companies which finance a larger portion of their financial resources through long-term borrowing and have higher financial leverage, experience a return that is proportional to the level of risk endured. However, as the amount of long-term debt increases, this return decreases. In companies with fewer loan facilities, there is no meaningful relationship between return and total debt ratio.
The impact of long-term financing on the company's return level is among the topics of interest to both creditors and investors. Therefore, this study aims to investigate this issue by examining a sample of companies listed on the Tehran Stock Exchange during the years 2005 to 2011, focusing on the financial leverage effect on the company's return. Of course, in order to achieve suitable results, the two groups of debt have been categorized based on the ratio of debt to total assets. The findings indicate that companies which finance a larger portion of their financial resources through long-term borrowing and have higher financial leverage, experience a return that is proportional to the level of risk endured. However, as the amount of long-term debt increases, this return decreases. In companies with fewer loan facilities, there is no meaningful relationship between return and total debt ratio. This article examines how human values, media engagement, and sociopolitical events shape immigration attitudes across Europe, with a particular focus on understanding the immigration attitudes of European managers, using other workers as a comparison group. Drawing on European Social Survey data from 2016 to 2023 (Rounds 8–11), this study integrates Schwartz’s theory of basic human values with media sociology to explore the interactive effects of value orientations and information exposure. Using multilevel linear modelling, the analysis reveals that self-esteem values and structured political news consumption are consistently associated with more inclusive immigration attitudes. While managers generally hold slightly more positive views than other workers do, these differences become more pronounced in contexts of high political media engagement. The impact of general internet use varies across countries, highlighting the importance of national media environments. Temporal fluctuations—particularly during the COVID-19 pandemic and the war in Ukraine—further demonstrate how crises interact with value–media dynamics. This study contributes to understanding the shaping and reinforcement of inclusive attitudes within Europe's evolving information landscape by combining individual, occupational, and contextual factors.
This article examines how human values, media engagement, and sociopolitical events shape immigration attitudes across Europe, with a particular focus on understanding the immigration attitudes of European managers, using other workers as a comparison group. Drawing on European Social Survey data from 2016 to 2023 (Rounds 8–11), this study integrates Schwartz’s theory of basic human values with media sociology to explore the interactive effects of value orientations and information exposure. Using multilevel linear modelling, the analysis reveals that self-esteem values and structured political news consumption are consistently associated with more inclusive immigration attitudes. While managers generally hold slightly more positive views than other workers do, these differences become more pronounced in contexts of high political media engagement. The impact of general internet use varies across countries, highlighting the importance of national media environments. Temporal fluctuations—particularly during the COVID-19 pandemic and the war in Ukraine—further demonstrate how crises interact with value–media dynamics. This study contributes to understanding the shaping and reinforcement of inclusive attitudes within Europe's evolving information landscape by combining individual, occupational, and contextual factors. This review investigates the impact of personal and contextual factors on health-seeking behaviours in terms of health-related information and healthcare service needs and utilization among asylum seekers, refugees, and undocumented immigrants using an adapted framework based on an extended Longo health information model. The 73 peer-reviewed records included in this systematic review were obtained from WoS, Ebsco, and Scopus. This review shows that culture, religion, policy, and systematic inequalities may play three different roles for our studied population, including facilitators, barriers, and health-related information sources. The findings indicated that providing universal health-related information and healthcare services may not meet all of the healthcare needs of our study population. As a result, healthcare providers must take a cross-cultural approach when designing, developing, and delivering specific health promotion programmes, treating patients with respect and attention, and providing health-related information and healthcare services based on ethnic, cultural, religious, and migration statuses.
This review investigates the impact of personal and contextual factors on health-seeking behaviours in terms of health-related information and healthcare service needs and utilization among asylum seekers, refugees, and undocumented immigrants using an adapted framework based on an extended Longo health information model. The 73 peer-reviewed records included in this systematic review were obtained from WoS, Ebsco, and Scopus. This review shows that culture, religion, policy, and systematic inequalities may play three different roles for our studied population, including facilitators, barriers, and health-related information sources. The findings indicated that providing universal health-related information and healthcare services may not meet all of the healthcare needs of our study population. As a result, healthcare providers must take a cross-cultural approach when designing, developing, and delivering specific health promotion programmes, treating patients with respect and attention, and providing health-related information and healthcare services based on ethnic, cultural, religious, and migration statuses. As an immigrant who moved to Finland permanently, I have experienced the significant challenges of using the Finnish healthcare system, such as dealing with the dental appoint-ment booking system in Turku, which was accessible only in the local languages, either in Finnish or Swedish.When I arrived, I had to overcome language barriers, unfamiliar medical practices, and a culture different from my home country. These challenges are common for many im-migrants in the Nordic countries, not just me. This experience motivated me to pursue myacademic research into how immigrants’ access and use health-related information and ser-vices in Nordic countries, as well as what barriers they face. Furthermore, I noticed a lack of existing research in this area, which reinforced my commitment to investigating this topic.Health information refers to a broad spectrum of information, such as details about different available health services, disease prevention methods, and health promotion pro-grammes in a country. Health information is accessible through different mediums.For immigrants, reliable and comprehensive health information is absolutely neces-sary—it bridges the gap between an unfamiliar healthcare system and their specific health needs, facilitating informed decisions about their health needs, understanding their medical rights, and navigating the available health-related information and services in a new country.Immigrants face many barriers when accessing healthcare services and information in a new country. Not only are these barriers logistical and linguistic, but they also have deep roots in the beliefs, perceptions, traditions, cultures, and habits that shapethe immigrants’ health-seeking behaviours. In many cultures, it is common to receive immediate medications for any minor illness—a practice that contrasts sharply with the Nordic approach, where doc-tors typically conduct detailed medical examinations before prescribing any medication. This difference in practice can lead to misunderstandings and feelings among immi-grants about receiving inadequate care because they expect immediate remedies and per-ceive the care as unnecessarily delayed.
As an immigrant who moved to Finland permanently, I have experienced the significant challenges of using the Finnish healthcare system, such as dealing with the dental appoint-ment booking system in Turku, which was accessible only in the local languages, either in Finnish or Swedish.When I arrived, I had to overcome language barriers, unfamiliar medical practices, and a culture different from my home country. These challenges are common for many im-migrants in the Nordic countries, not just me. This experience motivated me to pursue myacademic research into how immigrants’ access and use health-related information and ser-vices in Nordic countries, as well as what barriers they face. Furthermore, I noticed a lack of existing research in this area, which reinforced my commitment to investigating this topic.Health information refers to a broad spectrum of information, such as details about different available health services, disease prevention methods, and health promotion pro-grammes in a country. Health information is accessible through different mediums.For immigrants, reliable and comprehensive health information is absolutely neces-sary—it bridges the gap between an unfamiliar healthcare system and their specific health needs, facilitating informed decisions about their health needs, understanding their medical rights, and navigating the available health-related information and services in a new country.Immigrants face many barriers when accessing healthcare services and information in a new country. Not only are these barriers logistical and linguistic, but they also have deep roots in the beliefs, perceptions, traditions, cultures, and habits that shapethe immigrants’ health-seeking behaviours. In many cultures, it is common to receive immediate medications for any minor illness—a practice that contrasts sharply with the Nordic approach, where doc-tors typically conduct detailed medical examinations before prescribing any medication. This difference in practice can lead to misunderstandings and feelings among immi-grants about receiving inadequate care because they expect immediate remedies and per-ceive the care as unnecessarily delayed. Purpose
Purpose The purpose of this study is to explore health information environment and behaviours of Persian-speaking immigrants in Finland during the COVID-19 pandemic, utilising information chaos framework. Between January to March 2022, semi-structured interviews were conducted with a sample of 18 participants, using an adapted framework of information chaos and previous research as a guide for the interview questions.
The purpose of this study is to explore health information environment and behaviours of Persian-speaking immigrants in Finland during the COVID-19 pandemic, utilising information chaos framework. Between January to March 2022, semi-structured interviews were conducted with a sample of 18 participants, using an adapted framework of information chaos and previous research as a guide for the interview questions. Over the course of the last few decades, the Nordic countries are facing a change in their population structure, with a growing number of immigrants including people with asylum-seeking and refugee backgrounds. Almost three million people have moved to the Nordic countries in the last decade (Nordic Welfare Centre, 2017). For example, in Norway the number of asylum seekers for 2015 was 31,150 and the number of refugees for 2021 was 46,042 (Macro-trends, 2022; Statista, 2022). However, it should be noted that these individ-uals (asylum seekers and refugees) have diverse cultural and ethnical back-grounds, which means they may have different approaches toward seeking health information or healthcare services in their host country (Ahmadinia et al., 2021). Providing adequate and timely health information services for these people is one of the main challenges of the Nordic healthcare system (Haj-Younes et al., 2022). Therefore, a primary step to overcome this challenge is to understand what health-related information and healthcare services these individuals might need. This study aims to address this research gap by inves-tigating their information seeking behaviour from the perspective of cultural and ethnical background. Health information-seeking behaviour and health-care-seeking behaviour are two main key terms in this study. Health informa-tion-seeking behaviour refers to any situation in which an individual needs or uses any health-related information, while healthcare seeking behaviour refers to any activity undertaken by an individual who perceived himself to have a health concern, or to be sick, for the purpose of finding an appropriate reme-dy (Lalazaryan and Zare-Farashbandi, 2014; Ward et al., 1997). This extend-ed abstract, is a part of larger study including interviews also in Finland and Sweden, and presents preliminary findings of an original qualitative study on people with asylum seeking background and their health seeking behaviour in terms of health-related needs and utilisation in Norway.
Over the course of the last few decades, the Nordic countries are facing a change in their population structure, with a growing number of immigrants including people with asylum-seeking and refugee backgrounds. Almost three million people have moved to the Nordic countries in the last decade (Nordic Welfare Centre, 2017). For example, in Norway the number of asylum seekers for 2015 was 31,150 and the number of refugees for 2021 was 46,042 (Macro-trends, 2022; Statista, 2022). However, it should be noted that these individ-uals (asylum seekers and refugees) have diverse cultural and ethnical back-grounds, which means they may have different approaches toward seeking health information or healthcare services in their host country (Ahmadinia et al., 2021). Providing adequate and timely health information services for these people is one of the main challenges of the Nordic healthcare system (Haj-Younes et al., 2022). Therefore, a primary step to overcome this challenge is to understand what health-related information and healthcare services these individuals might need. This study aims to address this research gap by inves-tigating their information seeking behaviour from the perspective of cultural and ethnical background. Health information-seeking behaviour and health-care-seeking behaviour are two main key terms in this study. Health informa-tion-seeking behaviour refers to any situation in which an individual needs or uses any health-related information, while healthcare seeking behaviour refers to any activity undertaken by an individual who perceived himself to have a health concern, or to be sick, for the purpose of finding an appropriate reme-dy (Lalazaryan and Zare-Farashbandi, 2014; Ward et al., 1997). This extend-ed abstract, is a part of larger study including interviews also in Finland and Sweden, and presents preliminary findings of an original qualitative study on people with asylum seeking background and their health seeking behaviour in terms of health-related needs and utilisation in Norway. Literature on minorities' health-related information seeking shows that minorities, like non-minorities, require access to accurate and timely information, but they also need information in a range of languages and from a variety of sources. Health-related information seeking behaviour of Persian-speaking minorities living in Finland, explicitly focused on the COVID-19 pandemic situation, was investigated. Eighteen semi-structured interviews were conducted, and the extended Longo Health Information Model was used as a theoretical lens for analysing the data. The results point to several factors that can improve the outcome of minorities' health-related information seeking behaviours and activities, such as providing information related to their personal health, a deeper understanding of factors influencing the quality of health conditions at the individual or household level and broadcasting the latest health-related information in different languages and emphasize the needs for mental health-related information and services. The findings suggest that not only healthcare providers, immigration officials, and policymakers should be aware of the specific health-related information that minorities require, seek, and use during times of adversity, but also the extent to which how the identified factors influence the process of minorities' seeking health-related information.
Literature on minorities' health-related information seeking shows that minorities, like non-minorities, require access to accurate and timely information, but they also need information in a range of languages and from a variety of sources. Health-related information seeking behaviour of Persian-speaking minorities living in Finland, explicitly focused on the COVID-19 pandemic situation, was investigated. Eighteen semi-structured interviews were conducted, and the extended Longo Health Information Model was used as a theoretical lens for analysing the data. The results point to several factors that can improve the outcome of minorities' health-related information seeking behaviours and activities, such as providing information related to their personal health, a deeper understanding of factors influencing the quality of health conditions at the individual or household level and broadcasting the latest health-related information in different languages and emphasize the needs for mental health-related information and services. The findings suggest that not only healthcare providers, immigration officials, and policymakers should be aware of the specific health-related information that minorities require, seek, and use during times of adversity, but also the extent to which how the identified factors influence the process of minorities' seeking health-related information. Purpose
Purpose Empowering individuals through e-health can be considered as the current trend in developing healthcare services and devices. The aim of this article is to shed light on availability, benefits, and limitations of using these services and devices in people’s everyday life. This study is a descriptive review based on a non-exhaustive selection of previous studies that define information exchange, information formats, opportunities, and restrictions of e-health technologies. The main focus of this study is on presenting available e-health services and devices while describing their benefits and limitations. This approach has the potential to provide new insights into the future development and integration of e-health into the healthcare system of a country. The idea behind this review is to provide a better understanding of e-health services for authorities, healthcare professionals, individuals, and related beneficiaries.
Empowering individuals through e-health can be considered as the current trend in developing healthcare services and devices. The aim of this article is to shed light on availability, benefits, and limitations of using these services and devices in people’s everyday life. This study is a descriptive review based on a non-exhaustive selection of previous studies that define information exchange, information formats, opportunities, and restrictions of e-health technologies. The main focus of this study is on presenting available e-health services and devices while describing their benefits and limitations. This approach has the potential to provide new insights into the future development and integration of e-health into the healthcare system of a country. The idea behind this review is to provide a better understanding of e-health services for authorities, healthcare professionals, individuals, and related beneficiaries. During the ongoing outbreak of coronavirus people acquire and exchange health information about COVID-19 through different communication chan-nels. It is important to understand the role of individuals as information sources, and gain understanding on health information seeking behavior among language minorities during a pandemic.Lalazaryan & Zare-Farashbandi (2014) described health information seeking behavior as any individual’s activities that are related to seeking, obtaining, and making use of health information either regarding illnesses or treatments. In a pandemic, the health information seeking focus may change more towards securing one’s own health and supporting the close ones in the same crisis (Dreisiebner, März, Mandl, 2020). World Health Organisation (WHO) declared COVID-19 as a public health emergency of international concern (Jee, 2020; WHO, 2020). A pandemic raises feelings like fear, worry and anxiety. Mental health concerns have been raised in tow of the pandemic because of numerous reasons. One of them is the isolation millions of people have endured during the first and the ongoing second wave of COVID-19. WHO has established mental health recommen-dations of how individuals can care for their mental health during times of crisis. In these recommendations family and friends play a role, for instance in following ways: “keep in touch with friends and family”, “establish a support network”, “develop a feeling of belonging to the collective care process” (WHO, 2018).
During the ongoing outbreak of coronavirus people acquire and exchange health information about COVID-19 through different communication chan-nels. It is important to understand the role of individuals as information sources, and gain understanding on health information seeking behavior among language minorities during a pandemic.Lalazaryan & Zare-Farashbandi (2014) described health information seeking behavior as any individual’s activities that are related to seeking, obtaining, and making use of health information either regarding illnesses or treatments. In a pandemic, the health information seeking focus may change more towards securing one’s own health and supporting the close ones in the same crisis (Dreisiebner, März, Mandl, 2020). World Health Organisation (WHO) declared COVID-19 as a public health emergency of international concern (Jee, 2020; WHO, 2020). A pandemic raises feelings like fear, worry and anxiety. Mental health concerns have been raised in tow of the pandemic because of numerous reasons. One of them is the isolation millions of people have endured during the first and the ongoing second wave of COVID-19. WHO has established mental health recommen-dations of how individuals can care for their mental health during times of crisis. In these recommendations family and friends play a role, for instance in following ways: “keep in touch with friends and family”, “establish a support network”, “develop a feeling of belonging to the collective care process” (WHO, 2018). In this paper, Qoros automotive manufacturing company, which is aiming at expanding their market in Europe, will be analyzed. In this case, the challenges that the aforementioned company has faced will be explained and some recommendations regarding marketing, strategy, production methods and other related issues based on competitive intelligence models like SWOT, Porter's Five Forces Analysis, ADL Matrix, and other related theories will be provided.
In this paper, Qoros automotive manufacturing company, which is aiming at expanding their market in Europe, will be analyzed. In this case, the challenges that the aforementioned company has faced will be explained and some recommendations regarding marketing, strategy, production methods and other related issues based on competitive intelligence models like SWOT, Porter's Five Forces Analysis, ADL Matrix, and other related theories will be provided. Currently, organizations – must have a plan to achieve their future objectives. In this case, an information strategy facilitates greater success when planning for the future in any organization. Research design, data, and methodology – The core objective of the project was to explore the information infrastructure of Walkbase in a discursive manner. We started the project by providing a description of the firm, which facilitates retail outlets using in-store analytical devices. Results – We conclude that the management of Walkbase revised its current information structure to implement a more structured one that might be included in a long-term investment. On such an occasion, management can prioritize the component to develop first. Conclusions – Along with our results, we also described the business, its products, its facilities, and how it can serve different industries. Finally, we left the prioritization decision within the framework’s components to top management.
Currently, organizations – must have a plan to achieve their future objectives. In this case, an information strategy facilitates greater success when planning for the future in any organization. Research design, data, and methodology – The core objective of the project was to explore the information infrastructure of Walkbase in a discursive manner. We started the project by providing a description of the firm, which facilitates retail outlets using in-store analytical devices. Results – We conclude that the management of Walkbase revised its current information structure to implement a more structured one that might be included in a long-term investment. On such an occasion, management can prioritize the component to develop first. Conclusions – Along with our results, we also described the business, its products, its facilities, and how it can serve different industries. Finally, we left the prioritization decision within the framework’s components to top management. This paper evaluates the performance of the top 50 companies listed on the Tehran Stock Exchange from 2006 to 2010. A non-probability sampling method was used to select companies with positive liquidity, high turnover, and significant market impact. Using post-modern portfolio theory, the study applied EROV, Sortino, and M³ ratios to assess performance. Statistical analysis using ANOVA and the post-hoc Tukey test revealed significant differences in company performance. However, the results indicated that these companies did not outperform the market. Therefore, the researchers recommend incorporating additional financial and economic factors when selecting the top 50 companies.
This paper evaluates the performance of the top 50 companies listed on the Tehran Stock Exchange from 2006 to 2010. A non-probability sampling method was used to select companies with positive liquidity, high turnover, and significant market impact. Using post-modern portfolio theory, the study applied EROV, Sortino, and M³ ratios to assess performance. Statistical analysis using ANOVA and the post-hoc Tukey test revealed significant differences in company performance. However, the results indicated that these companies did not outperform the market. Therefore, the researchers recommend incorporating additional financial and economic factors when selecting the top 50 companies. Organizational behavior is closely linked to culture and structure, making these factors essential considerations in strategic decision-making. This paper begins by defining organizational culture, structure, and behavior. It then explores the relationship between culture and structure and their impact on behavior. Additionally, we examine various approaches to work subdivision at both the organizational and unit levels. To gain a deeper understanding of organizations, we analyze organizational behavior, culture, and structure as fundamental components of an organization’s framework and present their interrelationships.
Organizational behavior is closely linked to culture and structure, making these factors essential considerations in strategic decision-making. This paper begins by defining organizational culture, structure, and behavior. It then explores the relationship between culture and structure and their impact on behavior. Additionally, we examine various approaches to work subdivision at both the organizational and unit levels. To gain a deeper understanding of organizations, we analyze organizational behavior, culture, and structure as fundamental components of an organization’s framework and present their interrelationships. This study empirically analyzes the impact of financing methods on a company’s capital structure. To achieve this, companies listed on the Tehran Stock Exchange from 2006 to 2009 were categorized into two groups: those with high leverage and those with high stock issuance. Their performance was then evaluated using the Capital Asset Pricing Model (CAPM) and capital structure theories. By applying CAPM, we calculated the risks and expected returns for both groups and compared them to each other and the market. Statistical tests, including F-Levene and Student’s t-test, were used to validate the assumptions. The results indicate that companies financing through stock issuance exhibited lower risk and higher returns. Consequently, this group demonstrated better performance against systematic risk and created more value for shareholders.
This study empirically analyzes the impact of financing methods on a company’s capital structure. To achieve this, companies listed on the Tehran Stock Exchange from 2006 to 2009 were categorized into two groups: those with high leverage and those with high stock issuance. Their performance was then evaluated using the Capital Asset Pricing Model (CAPM) and capital structure theories. By applying CAPM, we calculated the risks and expected returns for both groups and compared them to each other and the market. Statistical tests, including F-Levene and Student’s t-test, were used to validate the assumptions. The results indicate that companies financing through stock issuance exhibited lower risk and higher returns. Consequently, this group demonstrated better performance against systematic risk and created more value for shareholders. This study aims to evaluate the functionality and impact of portfolio management in investment companies actively operating in the Tehran Stock Exchange between 2005 and 2010. The assessment is based on modern and post-modern portfolio theories using Sharpe, Sortino, and Sterling ratios. The first hypothesis was tested through statistical analysis of variance (ANOVA) and pairwise mean comparisons using the LSD pre-test. The results indicate that the performance of investment companies varies according to the Sharpe, Sortino, and Sterling ratios, with Sterling’s ratio showing a slightly better performance. The second hypothesis compared the performance of investment companies to the overall market. Except for the Sortino ratio, the other metrics demonstrated that investment companies performed better than the market. Finally, the results of the Kruskal-Wallis test and Chi-Square statistic confirmed that all three ratios provide consistent rankings of investment companies.
This study aims to evaluate the functionality and impact of portfolio management in investment companies actively operating in the Tehran Stock Exchange between 2005 and 2010. The assessment is based on modern and post-modern portfolio theories using Sharpe, Sortino, and Sterling ratios. The first hypothesis was tested through statistical analysis of variance (ANOVA) and pairwise mean comparisons using the LSD pre-test. The results indicate that the performance of investment companies varies according to the Sharpe, Sortino, and Sterling ratios, with Sterling’s ratio showing a slightly better performance. The second hypothesis compared the performance of investment companies to the overall market. Except for the Sortino ratio, the other metrics demonstrated that investment companies performed better than the market. Finally, the results of the Kruskal-Wallis test and Chi-Square statistic confirmed that all three ratios provide consistent rankings of investment companies. This study explores the evolution of the Capital Asset Pricing Model (CAPM) by integrating additional financial risk factors, including liquidity risks, downside risks, unexpected event risks, and operational and economic risks. These modifications enhance the model’s efficiency, leading to improved interpretations of market conditions and portfolio structures. As CAPM evolves, new variants provide better insights for financial managers, analysts, and investors, helping them assess both the advantages and limitations of these models in decision-making.
This study explores the evolution of the Capital Asset Pricing Model (CAPM) by integrating additional financial risk factors, including liquidity risks, downside risks, unexpected event risks, and operational and economic risks. These modifications enhance the model’s efficiency, leading to improved interpretations of market conditions and portfolio structures. As CAPM evolves, new variants provide better insights for financial managers, analysts, and investors, helping them assess both the advantages and limitations of these models in decision-making. This paper analyzes the performance of investment companies listed on the Tehran Stock Exchange that engaged in active portfolio management from 2006 to 2010, using the Sharpe, Treynor, and Sortino ratios. To gain a deeper understanding of their performance, the study also incorporates additional measures, including portfolio turnover, liquidity, size, and diversification. After collecting the necessary test data, statistical tests such as Kolmogorov-Smirnov and Shapiro-Wilk were conducted, revealing that the data distribution was not normal. Consequently, the hypotheses were tested using nonparametric methods. The findings of the first hypothesis, evaluated using Friedman and Wilcoxon tests, indicate that the companies demonstrated stronger control over systematic risk compared to other risk components. The results of the second hypothesis, analyzed using a combination of ANOVA and Multiple ANOVA, suggest that portfolio turnover had a more significant and positive impact on company performance than the other evaluated measures. This implies that investors can identify companies with high portfolio turnover and superior performance, even when other measures, such as liquidity and diversification, are relatively lower.
This paper analyzes the performance of investment companies listed on the Tehran Stock Exchange that engaged in active portfolio management from 2006 to 2010, using the Sharpe, Treynor, and Sortino ratios. To gain a deeper understanding of their performance, the study also incorporates additional measures, including portfolio turnover, liquidity, size, and diversification. After collecting the necessary test data, statistical tests such as Kolmogorov-Smirnov and Shapiro-Wilk were conducted, revealing that the data distribution was not normal. Consequently, the hypotheses were tested using nonparametric methods. The findings of the first hypothesis, evaluated using Friedman and Wilcoxon tests, indicate that the companies demonstrated stronger control over systematic risk compared to other risk components. The results of the second hypothesis, analyzed using a combination of ANOVA and Multiple ANOVA, suggest that portfolio turnover had a more significant and positive impact on company performance than the other evaluated measures. This implies that investors can identify companies with high portfolio turnover and superior performance, even when other measures, such as liquidity and diversification, are relatively lower. The aim of this paper is to evaluate the performance of top 50 Companies listed in Tehran Stock Exchange. This study was performed on the companies that were active from 2006 until 2010. The paper applied non-probable method in order to choose companies, which had positive liquidity, high turnover and high effect on the market. With regard to post modern portfolio theory, the researchers used EROV, SORTINO, and M3 ratios. The results of statistical analyzing with ANOVA and POST TOKEY test indicated that the performance of these companies is different, and they didn’t have better performance than market. Therefore the researchers suggest applying more financial and economic based factors to choose top 50 companies.
The aim of this paper is to evaluate the performance of top 50 Companies listed in Tehran Stock Exchange. This study was performed on the companies that were active from 2006 until 2010. The paper applied non-probable method in order to choose companies, which had positive liquidity, high turnover and high effect on the market. With regard to post modern portfolio theory, the researchers used EROV, SORTINO, and M3 ratios. The results of statistical analyzing with ANOVA and POST TOKEY test indicated that the performance of these companies is different, and they didn’t have better performance than market. Therefore the researchers suggest applying more financial and economic based factors to choose top 50 companies. The aim of this article is to provide a comprehensive review on different theories and hypothesis in regard with achieving an optimal capital structure. Many researchers believed that capital structure includes share issuance, private investment, bank debt, business debts, leasing contracts, tax debt, retirement debt, deferred compensation for executives and employees, deposits, product related-debt and other probable debt. These theories and hypothesis include: Net income, Net operational income, Traditional approach theory, Miller and Modigliani theory, Static trade–off theory, Asymmetric of the information hypothesis, Pecking order theory, Signaling theory, Agency cost theory, Free cash flow hypothesis, Dynamic trade-off theory and Market Timing theory. By applying these theories, the analysts will be able to reach a maximum return with minimum risk while they increase the value of corporation. Because of the close relationship between profitability and capital structure, this paper is going to suggest a new model called genetic algorithm model by using support vector regression and profitability factors for obtaining an international range of optimal capital structure.
The aim of this article is to provide a comprehensive review on different theories and hypothesis in regard with achieving an optimal capital structure. Many researchers believed that capital structure includes share issuance, private investment, bank debt, business debts, leasing contracts, tax debt, retirement debt, deferred compensation for executives and employees, deposits, product related-debt and other probable debt. These theories and hypothesis include: Net income, Net operational income, Traditional approach theory, Miller and Modigliani theory, Static trade–off theory, Asymmetric of the information hypothesis, Pecking order theory, Signaling theory, Agency cost theory, Free cash flow hypothesis, Dynamic trade-off theory and Market Timing theory. By applying these theories, the analysts will be able to reach a maximum return with minimum risk while they increase the value of corporation. Because of the close relationship between profitability and capital structure, this paper is going to suggest a new model called genetic algorithm model by using support vector regression and profitability factors for obtaining an international range of optimal capital structure. This study introduces the development and modifications of the widely used standard capital asset pricing model (CAPM). Many modifications are applied to the model’s challenging financial variables such as: financial risk factors, liquidity risks, downside risks, risk of non expected events, and economic and operational risk factors. Efficiency of the model is increased when applying various challenging financial variables. As a result of the gradual CAPM developments, various new models will present better interpretations of market conditions in economic units and portfolio structure. Furthermore, this study will show the importance of applying the new models advantages and disadvantages for financial managers, financial analysts and investors.
This study introduces the development and modifications of the widely used standard capital asset pricing model (CAPM). Many modifications are applied to the model’s challenging financial variables such as: financial risk factors, liquidity risks, downside risks, risk of non expected events, and economic and operational risk factors. Efficiency of the model is increased when applying various challenging financial variables. As a result of the gradual CAPM developments, various new models will present better interpretations of market conditions in economic units and portfolio structure. Furthermore, this study will show the importance of applying the new models advantages and disadvantages for financial managers, financial analysts and investors. The aim of this study is to evaluate the functionality and effect of portfolio management of investment
The aim of this study is to evaluate the functionality and effect of portfolio management of investment This dissertation undertakes a comprehensive investigation into the health information behaviours and health service requirements of immigrants, asylum seekers, and refugees across Nordic countries of Norway, Finland, and Sweden. The study presents valuable findings concerning the complex interplay among cultural factors, social networks, and personal experiences, thereby deepening our current understanding of the health behaviours displayed by these communities. This study explicitly includes immigrants, asylum seekers, and those denied asylum, acknowledging that the circumstances and contexts in which people experience health information needs might then differ.
This dissertation undertakes a comprehensive investigation into the health information behaviours and health service requirements of immigrants, asylum seekers, and refugees across Nordic countries of Norway, Finland, and Sweden. The study presents valuable findings concerning the complex interplay among cultural factors, social networks, and personal experiences, thereby deepening our current understanding of the health behaviours displayed by these communities. This study explicitly includes immigrants, asylum seekers, and those denied asylum, acknowledging that the circumstances and contexts in which people experience health information needs might then differ. Health information seeking behavior is a widely discussed topic in the field of information studies. However, the current study is about observing and evaluating the efficiency of health information seeking behavior through E-Health service and devices. The main reason that motivated the researcher to carry out the current research was high cost of healthcare services in Finland. It is expected that health information obtained through electronic or online sources would help people to improve their health conditions. Therefore, this thesis is an empirical study on observing E-Health information seeking behavior and evaluating the efficiency of E-Health service and devices. In order to estimate the efficiency of E-Health service and products, this study considered some criteria generated by previous studies. These criteria were employed in the current study as indicators of the health information seeking efficiency.
Health information seeking behavior is a widely discussed topic in the field of information studies. However, the current study is about observing and evaluating the efficiency of health information seeking behavior through E-Health service and devices. The main reason that motivated the researcher to carry out the current research was high cost of healthcare services in Finland. It is expected that health information obtained through electronic or online sources would help people to improve their health conditions. Therefore, this thesis is an empirical study on observing E-Health information seeking behavior and evaluating the efficiency of E-Health service and devices. In order to estimate the efficiency of E-Health service and products, this study considered some criteria generated by previous studies. These criteria were employed in the current study as indicators of the health information seeking efficiency. This study evaluates the performance of investment companies listed on the Tehran Stock Exchange (TSE) by employing systematic and nonsystematic risk measures, the Capital Asset Pricing Model (CAPM), and Arbitrage Pricing Theory (APT). The research aims to provide a comprehensive assessment of the risk-return tradeoff in the Iranian capital market, analyzing the extent to which these financial theories can explain stock price movements and investment company performance. Using historical stock price data, market indices, and macroeconomic factors, the study measures systematic risk (beta) and diversifiable risk across selected investment firms. CAPM is utilized to determine expected returns based on market risk premiums, while APT identifies multiple economic and financial variables influencing asset returns. The findings highlight the efficiency of these models in assessing investment performance, offering insights into portfolio diversification strategies and risk management practices within the Iranian financial market. The study contributes to the existing literature on asset pricing models in emerging markets, providing valuable implications for investors, financial analysts, and policymakers in Iran.
This study evaluates the performance of investment companies listed on the Tehran Stock Exchange (TSE) by employing systematic and nonsystematic risk measures, the Capital Asset Pricing Model (CAPM), and Arbitrage Pricing Theory (APT). The research aims to provide a comprehensive assessment of the risk-return tradeoff in the Iranian capital market, analyzing the extent to which these financial theories can explain stock price movements and investment company performance. Using historical stock price data, market indices, and macroeconomic factors, the study measures systematic risk (beta) and diversifiable risk across selected investment firms. CAPM is utilized to determine expected returns based on market risk premiums, while APT identifies multiple economic and financial variables influencing asset returns. The findings highlight the efficiency of these models in assessing investment performance, offering insights into portfolio diversification strategies and risk management practices within the Iranian financial market. The study contributes to the existing literature on asset pricing models in emerging markets, providing valuable implications for investors, financial analysts, and policymakers in Iran.


{kind=link}